Дискретизация аналогового сигнала
Дискретизация аналогового сигнала
Первое, на что стоит обратить внимание, это — изменение амплитуды вдоль одной оси. Можно условиться, что это ось времени (хотя в принципе это несущественно для абстрактного примера).
и достоинства импульсного способа передачи
Глава 6.
Преобразование аналогового сигнала в цифровые коды
В главах 3, 4 и 5 были рассмотрены необходимость и достоинства импульсного способа передачи информации, необходимость и сущность двоичной системы счисления, на основе которой обеспечивается возможность кодирования десятичных чисел и составления кодовой таблицы. В данной главе рассмотрены последние этапы теории кодирования, а именно подготовка условий для кодирования условного аналогового сигнала, у которого отсутствуют какие бы то ни было заранее выделенные элементы.
Глава посвящена созданию таких искусственных элементов, которые позволяют использовать их в качестве дискретных элементов, подлежащих кодированию. Для вычисления кодовой таблицы из полученных дискретных элементов необходимо предусмотреть следующие процессы:
сначала искусственное разделение непрерывного сигнала на отдельные элементы — процесс дискретизации;
затем усреднение сигнала в пределах дискретного элемента и оценку по определенной дискретной шкале — процесс квантования;
и наконец, присвоение квантированному уровню условного кода — процесс кодирования сигнала.
Преобразование аналогового сигнала в цифровые коды
Глава 6 Преобразование аналогового сигнала в цифровые коды Различие и дискретность Принудительная дискретизация Конвертирование аналогового сигнала в цифровой Дискретизация аналогового сигнала Разбиение на равные интервалы Усреднение в пределах интервала дискретизации Квантование аналогового сигнала Кодирование аналогового сигнала
Кодирование аналогового сигнала
Кодирование аналогового сигнала
В предыдущем разделе сказано, что шкала квантования выбирается с заранее заданными уровнями. Действительно, как мы выяснили там же, квантованный сигнал, в отличие от исходного (аналогового сигнала), может принимать принципиально конечное число значений.
Эти значения, как правило, равны порядковому номеру уровня квантования, что позволяет легко создать условия для последующего кодирования, т. к. это число (номер уровня) легко представить комбинацией двоичных единиц — чисел в двоичной системе счисления. А мы уже знаем, что такие числа можно считать кодами уровней квантования.
Соответственно, данный этап преобразования номера уровня квантования в двоичный код называется кодированием.
Чем был обоснован выбор восьми уровней квантования? В данном конкретном случае только удобством последующего кодирования.
Если требуется получить восемь двоичных кодов, для этого, как мы уже знаем, достаточно всего трех двоичных разрядов.
Информацию о расчетах количества двоичных разрядов см. в главе 5.
Составим таблицу (табл. 6.1) кодов для восьми условных уровней квантования.
Таблица 6.1. Коды восьми уровней квантования
| Уровень квантования |
Двоичный код |
Уровень квантования |
Двоичный код |
||
| 0 |
000 |
4 |
100 |
||
| 1 |
001 |
5 |
101 |
||
| 2 |
010 |
6 |
110 |
||
| 3 |
011 |
7 |
111 |
||
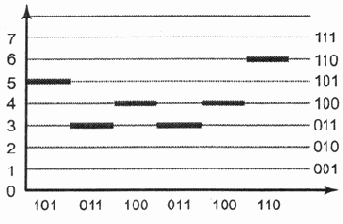
Теперь, используя эту кодовую таблицу, можно, наконец, представить исходный аналоговый сигнал (см. рис. 6.1) в виде последовательности двоичных кодов (рис. 6.8).
Если мы поменяем местами столбики таблицы (см. табл. 6.1), то получим кодовую таблицу для кодирования восьми уровней аналогового сигнала. В этой таблице представлены восемь двоичных чисел от 000 до 111, а их значениями являются соответствующие уровни квантования.
Конвертирование аналогового сигнала в цифровой
Конвертирование аналогового сигнала в цифровой
Я считаю, что в мире имеется бесконечное множество различных движений, происходящих непрерывно.
Рене Декарт
В непрерывном аналоговом сигнале нет отчетливо выделенных дискретных элементов, поэтому не представляется возможным составить элементарный список, не говоря уже о кодовой таблице. Если нельзя в строках списка (или в ячейках кодовой таблицы) располагать понятные и отличающиеся друг от друга, т. е. различимые, элементы, необходимо применить процедуру принудительной дискретизации.
В качестве условного примера рассмотрим некий аналоговый сигнал (рис. 6.1), в котором по определению отсутствуют дискретные элементы. Это означает, что априорно не существует такой таблицы, по которой можно было бы перечислить его составляющие.
Квантование аналогового сигнала
Квантование аналогового сигнала
Для сравнения значений, которые были усреднены (интегрированы) в пределах каждого дискретного интервала, необходимо ввести еще одну координату, расположенную перпендикулярно рассмотренной ранее, условно названной координатой "времени". С помощью новой координаты можно определить уровни усредненного сигнала в соответствии с заранее установленной шкалой.
По форме этот процесс в определенной степени напоминает дискретизацию, поскольку шкала также состоит из дискретных отсчетов и значения присваиваются не непрерывно, а с интервалом, т. е. дискретно. Действительно, можно сказать, что это — вторая дискретизация, которая тем не менее получила особое название "квантование".
Определение
Дискретность — это свойство, позволяющее различать однотипные или однородные объекты.
Определение
Дискретизация — это разделение на участки, в которых сигнал усредняется, В этом случае определяются отдельные, независимые друг от друга отсчеты, которые можно сравнивать между собой.
Усредненные значения — необходимый этап конвертирования аналогового сигнала в цифровой, но не конечный, а промежуточный. Следующим этапом является сравнение полученных значений по специальной шкале, т. е. квантование.
Определение
Квантование — это процедура замены величины усредненного дискретного отсчета ближайшим значением из набора фиксированных величин — уровней квантования.
Можно с сожалением признать, что квантование - это очередное "округление" величины усредненного отсчета: выбирается ближайшее значение по принципу округления (например, 11 округляется до 10, а 17 - до 20). Такое округление, разумеется, также вносит дополнительные искажения сигнала.
Пример-метафора
Считается, что любой коллектив — это совокупность отдельных индивидуальностей, как бы они друг с другом ни были связаны. Футбольную команду можно представить в виде списка, в котором каждому футболисту будет отведена отдельная строка, что дает основание для того, чтобы в эту строку добавить и условный код.
Что касается футболистов (как, впрочем, и других спортсменов), то каждый из них— постоянный участник процедур кодирования: любой футболист (или спортсмен) получает номер, который позволяет в данный отрезок времени однозначно идентифицировать участников матча или забега. Номер помогает различать спортсменов. Налицо классическая схема кодирования и декодирования (если совпадают таблицы кодирования).
Поэтому для того, чтобы закодировать информацию о конкретных людях (или о чем угодно) и заполнить столбик значений, необходимо однозначно выделить каждого из них. Это значит, что все значения, предназначенные для кодирования, должны отличаться друг от друга по какому-нибудь критерию.
Это и есть главное свойство, которое называется "дискретностью".
Пример-метафора
Работа по дискретизации элементов речи, или текста, и созданию алфавита языка выполнена задолго до компьютерных технологий, а задача последних оказалась относительно проста (когда уже существует готовый алфавит, хотя бы и неоптимальный с точки зрения удобства кодирования) — поставить в соответствие каждой букве числовые двоичные коды.
В случае с алфавитом какого бы то ни было языка задача упрощена тем, что к моменту кодирования букв программисты уже располагали конечным количеством элементов, им осталось только их пересчитать и определить, какое количество двоичных разрядов потребуется для этой цели. А затем поставить в соответствие каждому дискретному элементу свой код.
В любом случае кодовую таблицу легко создавать, имея в наличии алфавит, список, перечень или прейскурант.
Пример-метафора
Каждый студент группы имеет студенческий билет и зачетную книжку, из которых можно узнать не только его фамилию, но и другие отличительные сведения (прежде всего уровень успеваемости).
Безусловно, это касается не только студентов, но и любого человека. Каждый из нас "дискретен" по отношению ко всему человечеству. Но когда мы наблюдаем какую-либо огромную массу людей, скажем, на стадионе, нам достаточно трудно выделить отдельных представителей рода человеческого. Люди кажутся пестрым ковром, и чтобы найти человека, выделить его из этой огромной толпы, требуется особое умение или какой-либо оптический инструмент (например, бинокль).
Но представьте себе ситуацию, когда та область, которую нам предстоит кодировать, не имеет ясно выраженных элементов. По крайней мере, мы их перечислить не можем, не можем взять и "разложить по полочкам", не можем составить список от первого до последнего элемента.
Иногда выделение элементов действительно сопряжено со многими трудностями, даже в той области, которая уже исторически с ней справилась, но все равно при обучении всякий раз происходит повторение исторического пути. В качестве удачного примера с точки зрения дискретизации в предыдущем разделе мы рассмотрели пример букв (фонетического письма), однако на самом деле все не так просто.
Пример-метафора
Обратим внимание на то, что буквы фонетического алфавита (фонетического письма) — это знаки не совсем тех звуков, которые мы произносим. Когда мы говорим слово "молоко", мы произносим на самом деле три разных звука (очень нейтральный звук в первом слоге, почти звук "а" без ударения и звук "о" в ударной позиции), а на письме обозначаем одной и той же буквой "о". В данном случае получается, что звук "а", который мы действительно произносим, на самом деле буквой "а" не записывается. Поэтому существует наука фонология (раздел лингвистики), которая как раз занимается тем, что вводит такое понятие, как фонема. И вот фонема это не просто чистый звук "а", это некий ареал.
Скажем, в слове "молоко" это фонема не "а", хотя мы фактически ее произносим. А на самом деле буква "о", это вариант "а", причем это не просто "а", а нейтральный звук, в который "о" попадает, когда она безударна. То есть вот это "а", которое мы произносим в слове "молоко", — на самом деле вариант буквы "о".
Пример-метафора
Пока наши действия напоминают работу метронома. Действительно, мы разделили непрерывный сигнал на определенные длительности времени: скажем, каждую секунду происходит биение, и эти биения мы можем пронумеровать и сосчитать. Но то, что происходит между этими биениями, пока выпадает из фиксирования.
А почему? Ответ ясен: дискретные интервалы принципиально ничем не отличаются от сигнала в целом (кроме, разумеется, длительности). Ведь внутри интервалов такой же непрерывный фрагмент аналогового сигнала. В обоих случаях — непрерывные сигналы. И кажется, что решение состоит в уменьшении интервалов.
Пример-метафора
Предположим, что в учебной канцелярии возникла необходимость сравнить успеваемость двух групп. Как это сделать? Понятно, что в обеих группах есть "отличники" и "двоечники", т. е. существует определенный разброс оценок по разным дисциплинам. Если же будут выбраны усредненные значения, не учитывающие разброса, то в общем (с неизбежными погрешностями) мы получим основания для того, чтобы сравнивать, т. к. располагаем дискретными значениями. Скажем, в одной группе средний балл получился равным 4,9, а в другой — 3,1. Понятно, что первая группа по успеваемости значительно превосходит вторую, хотя для двух конкретных студентов из этих групп это соотношение может быть несправедливым.
Конечно, в этом алгоритме есть недостатки, которые являются неизбежной платой за возможность сравнения. В той группе, где средний балл оказался равным 3,1, отдельный студент может иметь пятерки по всем предметам. Невзирая на это, вся группа числится в отстающих. Кого-то это может не устраивать, но такова объективная реальность, таков механизм, таков алгоритм.
Пример-метафора
Представьте себе график прибылей какого-либо предприятия. Этот график отображает информацию о каждом рабочем дне. Для прогнозирования необходима обобщенная информация, например помесячно.
Но с помощью такого ежедневного графика невозможно сравнивать помесячные доходы друг с другом (вспомните успеваемость группы по отдельным учащимся и по отдельным предметам), значения по дням имеют очень значительный разброс. Поэтому необходимо определить усредненные значения прибыли за каждый месяц. В результате вместо ежедневного графика получается график помесячный, который наглядно отображает уровни прибылей.
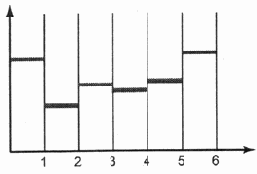
Стоит обратить внимание, что после процедуры усреднения аналоговый сигнал преобразуется в ступенчатую линию, которая, в общем, конечно, имитирует исходную кривую (рис. 6.5).
что мы рассматривали возможность кодирования
Вспомним, что мы рассматривали возможность кодирования студентов определенной группы или даже всего факультета. Если кого-то исключили, или кто-то перешел в другое учебное заведение, или девушка сменила фамилию по понятной причине, то это ведь не означает, что вся кодовая таблица распадается и возникает необходимость вновь ее формировать на каких-либо других принципах.
Кроме того, мы также получили
Кроме того, мы также получили таблицу, в которой произвольным образом присвоили коды четырем ахроматическим цветам.
Эти примеры приведены для того, чтобы можно было увидеть различие между списком студентов и списком цветов. Возможна ли ситуация, когда в кодовой таблице представлены, как у одного детского писателя, "четверть студента N" и "три четверти студента М"? Безусловно, нет. А у цвета это вполне возможно. Например, "сине-зеленый", "розово-фиолетовый" и т. д.
Итак, нам необходимо определить то свойство, без которого не обойтись при составлении кодовых таблиц. А только кодовая таблица позволит в дальнейшем использовать этот вид информации в компьютерных технологиях.
Каждый из нас вполне способен
Каждый из нас вполне способен отличить белое от черного. В языке существуют резко отличающиеся и не смешиваемые друг с другом (однозначные) понятия "белого" и "черного". Безусловно, иногда возможна неуверенность по поводу того, можем ли мы четко квалифицировать какой-нибудь реальный цвет как "белый" или как "черный". В одних условиях нам может казаться, что этот цвет очень светлый, почти белый, а в других — очень темный, почти черный.
Для компьютерных технологий "дискретный" является синонимом "целочисленный". Например, даже дробные числа должны получить особую форму дискретных чисел (кодов).
Если данные не дискретны, т. е. как бы размыты, процедура кодирования невозможна. В этом принципиальное различие компьютерного "мышления" и человеческого: сами-то мы часто оперируем чрезвычайно неопределенными понятиями — "искусство", "талант", "любовь", "счастье", "надежда".
Следует обратить внимание на то, что дискретность — это универсальное требование цифровых технологий, по сути процесс собственно дискретизации и процесс квантования — это различные виды дискретизации (разбиение непрерывного сигнала на отдельные отсчеты или уровни).
Принудительная дискретизация
Принудительная дискретизация
Фонетическое письмо определяет всю нашу культуру и всю нашу науку, вовсе не будучи обычным, рядовым явлением.
Жак Деррида
Выше мы пришли к выводу, что для того, чтобы составить кодовую таблицу, нам нужно наличие отдельных или, как говорят специалисты, — дискретных элементов. Поэтому мы и рассматривали элементы списка, или таблицы, которые отличаются друг от друга сами по себе (дискретны, как говорят, "по жизни"), т. е. каждый чем-то однозначно выделяется.
Разбиение на равные интервалы
Разбиение на равные интервалы
В качестве первой операции необходимо разбить эту ось на определенные интервалы, возможно, это и будут интервалы по времени (рис. 6.2).
Различие и дискретность
Различие и дискретность
Этот Виктор Перестукин решал задачу, и у него получилось, что траншею выкопали полтора землекопа.
Лия Гераскина
В конечном счете, всех интересует только то содержание, которое понятно и доступно человеку. А то, что происходит внутри компьютера, заботит хотя и большое количество специалистов, но все-таки их гораздо меньше тех, кто использует его в качестве инструмента.
Если вы вспомните главы, посвященные аппаратной части настольных издательских систем, то там утверждалось, что устройства ввода предназначены для преобразования соответствующей информации в цифровую форму, а устройства вывода, наоборот, для преобразования цифровых кодов в значения, понятные для восприятия человека.
Информацию о существующих в настоящее время устройствах ввода информации см. в части I.
Исходный аналоговый сигнал
Рис. 6.1. Исходный аналоговый сигнал
Разбиение аналогового сигнала на интервалы
Рис. 6.2. Разбиение аналогового сигнала на интервалы
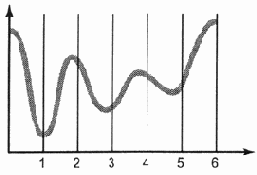
Цель такого разбиения проста — это единственный способ получения дискретных элементов, причем стоит обратить внимание, что применяется искусственный прием, который ранее мы определяли как "принудительная" дискретизация.
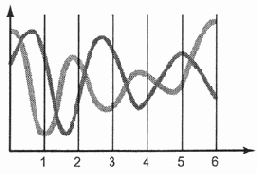
Два разных аналоговых...
Рис. 6.3. Два разных аналоговых сигнала с одинаковыми интервалами
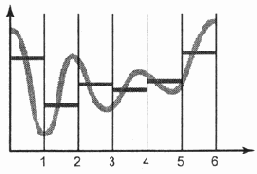
Усреднение сигналов...
Рис. 6.4. Усреднение сигналов в пределах "дискретов"
Вид ступенчатой линии сигнала после усреднения
Рис. 6.5. Вид ступенчатой линии сигнала после усреднения
На данном этапе можно уточнить определение дискретизации.
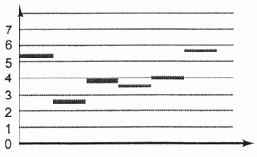
с восемью уровнями от
Рис. 6.6. Шкала квантования с восемью уровнями от 0 до 7
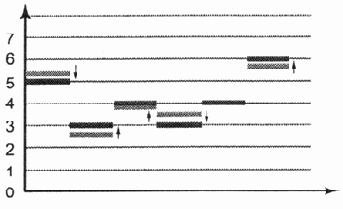
Аналоговый сигнал со значениями квантования
Рис. 6.7. Аналоговый сигнал со значениями квантования
Когда каждый дискретный элемент связывается с определенным набором уровней квантования, а исходный аналоговый сигнал преобразуется в последовательность стандартизированных значений, это и есть идеальная ситуация для последующего процесса кодирования.
Кодирование аналогового сигнала
Рис. 6.8. Кодирование аналогового сигнала
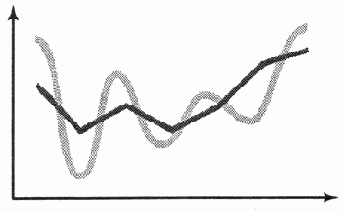
Эта таблица важна еще и потому, что она потребуется для процедуры обратного преобразования (рис. 6.9). Следует только обратить внимание на то, что аналоговый сигнал, синтезированный из цифрового сигнала, в нашем примере довольно значительно отличается от исходного аналогового сигнала (рис. 6.10), что, впрочем, создано специально.
Преобразованный аналоговый сигнал
Рис. 6.9. Преобразованный аналоговый сигнал
Различие исходного и преобразованного сигналов
Рис. 6.10. Различие исходного и преобразованного сигналов
Справка
Слово "дискретность" латинского происхождения: "discretus" — это причастие от глагола "discere", что переводится как "отделять", "разделять", следовательно, само слово означает "разделенный" или "отделенный".
Таким образом, необходимо сформулировать обязательное условие: все значения, подлежащие кодированию, должны быть дискретны.
Справка
Фонология (от греческих слов "phone", что означает "звук", и "логия" — "наука") — это раздел языкознания, изучающий структурные и функциональные закономерности звукового строя языка.
Справка
Фонема (от греческого слова "phonema", что означает "звук") — это единица языка, с помощью которой различаются и отождествляются морфемы и тем самым слова, т. к. она определяет совокупность различительных признаков. Например, в русской речи в словах "дам" и "там" представлены фонемы [д] и [т], которые различаются по признаку "глухость" и "звонкость". В русском языке выделены 44 фонемы, которые реализуется в речи в виде множества вариантов, число которых невозможно сосчитать. Напомним, что в алфавите русского языка используется 33 буквы.
Исходя из этого, понятно, что выделение фонетического алфавита, запись текста сопряжены с массой проблем (тем более что язык развивается, не стоит на месте). Кроме того, огромную роль играют индивидуальные особенности произношения, ведь даже дикторов, обладающих наиболее стандартизированным произношением, мы свободно отличаем друг от друга.
Поэтому до сих пор не удается в полной мере заставить компьютерное устройство преобразовывать речь в текст. Системы распознавания речи, так же, как и системы распознавания оптических образов, до конца не разработаны. Хотя существуют программы для превращения сканированных изображений страниц в текстовые, которые работают неплохо, но для этого требуется масса определенных условий. Существуют также системы распознавания речи, но они еще более несовершенны и имеют очень узкий диапазон.
Таким образом, даже в тех областях, в которых исторически выделены более или менее четкие дискретные элементы, существуют научные и теоретические проблемы. А уж что говорить о тех областях, где очевидная дискретность отсутствует!
Однако необходимость в компьютерной обработке и такой информации существует, поэтому перейдем к условиям, которые требуются для кодирования непрерывного потока аналогового сигнала.
Таким основополагающим условием является принудительная дискретизация, т. е. "искусственное создание" элементов. В этом случае искусственные элементы должны в какой-либо мере отражать характер информации, которая "подвергается принуждению", следовательно, возможны различные принципы дискретизации (линейная, пространственная, временная, а также их разные сочетания).
Для того чтобы наиболее наглядно представить процедуру принудительной дискретизации, рассмотрим абстрактный пример аналогового сигнала, который в конечном счете необходимо конвертировать в последовательность цифровых кодов.
Справка
Амплитуда происходит от латинского слова "amplitude", что переводится как "величина" и означает максимальное отклонение изменяющейся по определенному закону величины от среднего значения или от некоторого значения, условно принятого за нулевое.
Справка
Апория (от греческого слова "aporia", что означает "безвыходность") — это трудная или неразрешимая проблема, связанная с возникновением противоречия, с наличием аргумента против очевидного и общепринятого. Зенон из Элей (ок. 490—430 до н. э.) — представитель элейской школы, его считают основателем диалектики как искусства постижения истины посредством спора или истолкования противоположных мнений. Философ известен знаменитыми апориями, обосновывающими невозможность движения. Решение апории состоит в исключении бесконечного деления пространства и времени, что в реальной действительности принципиально невозможно.
В самом деле, мы пока не дали ясного ответа на вопрос: зачем было затеяно это деление на дискретные фрагменты?
Справка
Термин "квантование" происходит от латинского слова "quantum", что означает "сколько". Процедура оценки, или оценивания, т. е. получение ответа на вопрос "сколько" — это и есть процедура квантования.
Исходя из этой этимологии, вертикальная шкала называется шкалой квантования, а дискретные отсчеты на этой шкале — уровнями квантования. Это значит, что уровни квантования делят диапазон возможного изменения значений сигнала на конечное число интервалов. В общем случае шкалы могут быть как равномерными, так и неравномерными.
Процедура квантования необходима для привязки усредненных сигналов в дискретных интервалах к определенному набору значений со ступенчатым изменением (квантование сигнала по уровню).
Фактически же этот процесс означает оценку усредненного сигнала по заранее заданной шкале, предположим для простоты, с восемью равномерными уровнями: 0, 1, 2, 3, 4, 5, 6, 7 (рис. 6.6).
Справка
Для того чтобы реальный звуковой сигнал, поступающий на микрофон и индуцирующий непрерывный электрический сигнал, был оцифрован с приемлемым качеством, необходимо выполнять квантование не реже 40 000 тысяч раз в секунду, а фактически даже больше — именно 44 100 раз, что означает частоту 44,1 кГц.
Важная мысль
Кодовая таблица предполагает соответствующую таблицу квантования на другом устройстве. Если это не так, воспроизведение может радикально отличаться от требуемого.
Резюме
Для получения дискретных элементов в непрерывном потоке аналогового сигнала, в котором отсутствуют отдельные элементы, применяется принудительная дискретизация — разбиение потока на определенные равные интервалы. Полученные интервалы можно пронумеровать с помощью натурального ряда чисел.
Следущий шаг дискретизации — это усреднение, или интегрирование, непрерывно изменяющегося сигнала в пределах каждого отсчета. Аналоговый сигнал преобразуется в ступенчатую линию, которая в общем, конечно, имитирует исходную кривую с определенной (кстати, заранее заданной) погрешностью.
Для сравнения полученных усредненных значений вводится координата, с помощью которой можно определить уровни этого усредненного сигнала в соответствии с заранее установленной шкалой. Этот процесс соответствует второй дискретизации, которая получила название квантование. В результате процедуры квантования получают дискретные значения, привязанные к уровням квантования. Эти значения равны порядковому номеру уровня квантования, что позволяет легко создать условия для последующего кодирования.
Соответственно, следующий этап преобразования номера уровня квантования в двоичный код называется кодированием.
В данной части были рассмотрены два основных способа передачи информации: аналоговый и импульсный.
Аналоговый нам необходим по причинам того, что объективная информация (звук или изображение) представляет собой аналоговую форму, поэтому на этапах ввода и вывода информации приходится иметь дело с аналоговыми сигналами. Рассмотренные в данной части особенности достаточны для того, чтобы представлять себе, какие сигналы подлежат преобразованию в форму, "понятную" компьютеру.
С другой стороны, компьютерные технологии не обладают органами чувств и мышлением, которыми природа снабдила человека. Для их функционирования требуется самый простой и однообразный вид сигнала, каковым является импульсный.
В компьютерных технологиях основополагающую роль играет понятие бита, который определяется как минимальное количество информации, его использование обеспечивает количественное измерение информации. И поскольку двоичная система счисления идеально совпадает с понятием бита, это дает возможность передавать информацию одновременно с ее учетом.
Любое двоичное число — это совокупность битов, каждый бит — это один разряд, а разрядность двоичного числа — это количество знакомест (или количество разрядов, или количество битов), заранее отведенных для записи двоичного числа. Количество двоичных разрядов определяет количество кодов, которое равняется соответствующей степени числа "2".
Кодовый алфавит — это минимальный перечень элементов, а кодовая таблица — это совокупность кодов и их значений. Длина кодовой таблицы может быть произвольной, но ограничивается возможностями технической реализации.
Значение кода не является законом природы — это всякий раз результат условности, результат договоренности, закрепленный теми или иными стандартами.
В общем случае, кодовая таблица может включать любое содержание, если есть возможность подготовить его к кодированию, т. е. принудительно выделить дискретные элементы, даже если они носят искусственный характер.
Части I и II являются подготовительными для последующих основных частей, посвященных пиксельной и векторной графике. Часть III посвящена пиксельной графике, которая использует идентичные принципы кодирования. Часть IV представляет собой рассказ о векторной графике, которая также основана на дискретизации, но в несколько ином аспекте.
Усреднение в пределах интервала дискретизации
Усреднение в пределах интервала дискретизации
Ответ на заданный выше вопрос можно сформулировать таким образом: непрерывный поток информации, или непрерывный сигнал, подвергается разбиению на небольшие дискретные участки с совершенно определенной целью — получить на этих участках один-единственный отсчет (дискретный элемент). Сама по себе эта процедура, конечно, ничего не решает, но создает предпосылку для последующих шагов.
В качестве следующего шага необходимо выяснить, как в пределах интервала получить одно значение, один дискретный элемент?
Для того чтобы получить единственное значение в пределах этого "дискретного интервала", необходимо просто-напросто усреднить сигнал между границами этих "дискретов" (рис. 6.4).
Таким образом, следущий шаг этапа дискретизации — это усреднение, или интегрирование, непрерывно изменяющегося сигнала в пределах каждого отсчета.
Важная мысль
Все значения, подлежащие кодированию, должны быть дискретны.
Это означает, что располагая раздельными элементами, а проще говоря, располагая элементарным списком элементов, можно легко включить их в кодовую таблицу (или говоря наукообразно, "подвергнуть кодированию").
Важная мысль
Для создания дискретных элементов применяется искуссвенный прием — "принудительная" дискретизация.
В самом деле, выбранные интервалы принципиально никак не учитывают содержание сигнала, а хладнокровно "режут по живому" - - в этом суть процесса "принудительной" дискретизации.
В данном конкретном случае дискретизация является линейной, т. к. используется всего одна координата (одна линия, вдоль которой происходит разбиение на равные интервалы).
Однако следует попутно заметить, что
Однако следует попутно заметить, что такая идиллическая ситуация возможна только при том условии, что кодовые таблицы для соответствующего вида информации на входе и на выходе совпадают, т. е. при условии, что они в данной системе стандартизированы.
В этой главе мы обратим более пристальное внимание на другую половину кодовой таблицы, т. е. на столбец "значение". И первый важнейший вопрос: каким обязательным свойством должно обладать значение для того, чтобы его можно было закодировать?
в предыдущих главах нам удавалось
Кстати, в предыдущих главах нам удавалось составлять кодовые таблицы без упоминания этого свойства.
В части III эти процедуры
В части III эти процедуры будут рассмотрены на примере графических изображений.
Мы не рискнем назвать эту
Мы не рискнем назвать эту волну звуком, потому что на самом деле звук речи или музыкальный звук — это не просто какая-либо чистая волна. Более того, чистая волна как раз мало интересна. Музыкальные голоса ценятся, если в них присутствуют дополнительные звуки (обертоны — частичные тоны, звучащие выше и слабее основного тона, слиты с ним и на слух почти не распознаются). Наличие и сила каждого из них определяют тембр звука или голоса и его своеобразие, по которому мы как раз и опознаем человека.
В общем случае интервалы могут
В общем случае интервалы могут быть и разными, но тогда придется ответить на два вопроса: во-первых, как попасть в нужные, смысловые точки, а во-вторых, как передать с каждым дискретным интервалом значения разных длительностей. Не стоит забывать, что все указанные действия ориентированы на техническую реализацию. А техника "склонна" выполнять механические и однозначные действия.
Полученные интервалы очень полезно каким-либо образом "пометить", например пронумеровать с помощью натурального ряда чисел: О, 1, 2, 3 и т. д.
Можем ли мы считать, что процесс дискретизации закончен? Отнюдь нет. Ведь кривая аналогового сигнала, подвергнутая "принудительной дискретизации", нисколько не изменилась, получить какие бы то ни было элементы пока не удалось.
В самом деле, только количества "дискретов", на которое разделяется сигнал, явно недостаточно. Поскольку в этом случае (по количеству "дискретов") могут казаться равными все сигналы одинаковой длины, ведь они составляются из одинакового количества "дискретных интервалов", хотя внутри интервалов сигналы будут абсолютно разными (рис. 6.3).
Уменьшение интервалов, конечно, имеет определенное
Уменьшение интервалов, конечно, имеет определенное значение, например эта процедура определяет качество цифрового сигнала.
Однако на данном этапе, когда мы рассматриваем логические основания, необходимо понять, что принципиально деление на все более мелкие (до бесконечности) элементы данную проблему не решает.
Вспомним знаменитую апорию древнегреческого философа Зенона об Ахилле: чемпиону по бегу не удается догнать черепаху. Почему? Черепаха вышла, прошла какую-то часть своего пути прежде, чем начнет свой бег спортсмен. Но прежде, чем он пробежит свою половину пути, черепаха сдвинется на какое-то расстояние. И рассуждая строго логически, приходим к выводу, что нельзя догнать эту загадочно-логическую черепаху.
В содержательном смысле превращение фрагмента
В содержательном смысле превращение фрагмента непрерывного сигнала в одно-единственное значение является нетривиальной процедурой. Действительно, как выбрать наиболее характерное значение? Если бы анализом и отбором занимались люди, например музыканты, то понятно, что при очень небольшой производительности качество приближалось бы к оптимально художественному. На самом деле, для технической реализации необходимо применить стандартизированный прием, например использовать текущее значение в момент "биения" метронома. Этот нюанс уже зависит от конкретного технического решения.
Но поскольку за эту интеграцию "отвечает" вычислительная техника, необходимо принять максимально простой алгоритм. А самой простой процедурой в этой ситуации является усреднение (хотя возможен выбор минимального или максимального значения в интервале).
Этот алгоритм не носит, впрочем,
Этот алгоритм не носит, впрочем, всеобщего характера. Возможны и анекдотические случаи: скажем, средняя температура по больнице.
В результате усреднения (интеграции) сигнала в пределах диапазона дискретизации на графике появится множество средних значений. На каждом дискретном участке они отображаются линиями, параллельными горизонтальной оси.
в процессе квантования, называются шумом
Искажения сигнала, происходящие в процессе квантования, называются шумом квантования. Принципиально важно, что это искажение не может быть в дальнейшем устранено, т. к. шум квантования коррелирован с сигналом. В общем случае это искажение уменьшается при увеличении количества уровней квантования.
В результате процедуры квантования получают дискретные значения, привязанные к уровням квантования (рис. 6.7).