Алгоритм Хаффмана
Классический алгоритм Хаффмана
Один из классических алгоритмов, известных с 60-х годов. Использует только частоту появления одинаковых байт в изображении. Сопоставляет символам входного потока, которые встречаются большее число раз, цепочку бит меньшей длины. И, напротив, встречающимся редко — цепочку большей длины. Для сбора статистики требует двух проходов по изображению.
Для начала введем несколько определений.
Определение. Пусть задан алфавит Y ={a1, ..., ar}, состоящий из конечного числа букв. Конечную последовательность символов из Y
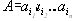
будем называть словом в алфавите Y
, а число n — длиной слова A. Длина слова обозначается как l(A).
Пусть задан алфавит W , W
={b1, ..., bq}. Через B
обозначим слово в алфавите W и через S(W
) — множество всех непустых слов в алфавите W
.
Пусть S=S(Y
) — множество всех непустых слов в алфавите Y
, и S' — некоторое подмножество множества S. Пусть также задано отображение F, которое каждому слову A, A?
S(Y ), ставит в соответствие слово
B=F(A), B? S(W
).
Слово В будем назвать кодом сообщения A, а переход от слова A к его коду — кодированием.
Определение. Рассмотрим соответствие между буквами алфавита Y и некоторыми словами алфавита W :
a1
— B1,
a2
— B2,
. . .
ar
— Br
Это соответствие называют схемой и обозначают через S
. Оно определяет кодирование следующим образом: каждому слову
из S'(W )=S(W
) ставится в соответствие слово
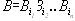
называются элементарными кодами. Данный вид кодирования называют алфавитным кодированием.
Определение. Пусть слово В имеет вид
B=B' B"
Тогда слово B'называется началом или префиксом слова B, а B" — концом слова B. При этом пустое слово L
и само слово B считаются началами и концами слова B.
Определение. Схема Sобладает свойством префикса, если для любых iи j(1?i, j? r, i? j) слово Bi
не является префиксом слова Bj.
Теорема 1. Если схема Sобладает свойством префикса, то алфавитное кодирование будет взаимно однозначным.
Предположим, что задан алфавит Y
={a1,..., ar} (r>1) и набор вероятностей p1, . . . , pr

появления символов a1,..., ar. Пусть, далее, задан алфавит W , W
={b1, ..., bq} (q>1). Тогда можно построить целый ряд схем S алфавитного кодирования
a1
— B1,
. . .
ar
— Br
обладающих свойством взаимной однозначности.
Для каждой схемы можно ввести среднюю длину lср, определяемую как математическое ожидание длины элементарного кода:

Длина lср
показывает, во сколько раз увеличивается средняя длина слова при кодировании со схемой S .
Можно показать, что lср
достигает величины своего минимума l*
на некоторой Sи определена как
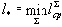
Определение. Коды, определяемые схемой S
с lср= l*, называются кодами с минимальной избыточностью, или кодами Хаффмана.
Коды с минимальной избыточностью дают в среднем минимальное увеличение длин слов при соответствующем кодировании.
В нашем случае, алфавит Y ={a1,..., ar} задает символы входного потока, а алфавит W
={0,1}, т.е. состоит всего из нуля и единицы.
Алгоритм построения схемы S
можно представить следующим образом:
Шаг 1. Упорядочиваем все буквы входного алфавита в порядке убывания вероятности. Считаем все соответствующие слова Bi
из алфавита W ={0,1} пустыми.
Шаг 2. Объединяем два символа air-1
и air
с наименьшими вероятностями pi
r-1 и pi
r в псевдосимвол a'{air-1 air} c вероятностью pir-1+pir. Дописываем 0 в начало слова Bir-1
(Bir-1=0Bir-1), и 1 в начало слова Bir
(Bir=1Bir).
Шаг 3. Удаляем из списка упорядоченных символов air-1
и air, заносим туда псевдосимвол a'{air-1air}. Проводим шаг 2, добавляя при необходимости 1 или ноль для всех слов Bi, соответствующих псевдосимволам, до тех пор, пока в списке не останется 1 псевдосимвол.
Пример: Пусть у нас есть 4 буквы в алфавите Y
={a1,..., a4} (r=4), p1=0.5, p2=0.24,
p3=0.15, p4=0.11

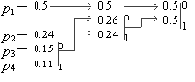
Производя действия, соответствующие 2-му шагу, мы получаем псевдосимвол с вероятностью 0.26 (и приписываем 0 и 1 соответствующим словам). Повторяя же эти действия для измененного списка, мы получаем псевдосимвол с вероятностью 0.5. И, наконец, на последнем этапе мы получаем суммарную вероятность 1.
Для того, чтобы восстановить кодирующие слова, нам надо пройти по стрелкам от начальных символов к концу получившегося бинарного дерева. Так, для символа с вероятностью p4, получим B4=101, для p3
получим B3=100, для p2
получим B2=11, для p1
получим B1=0. Что означает схему:
a1
— 0,
a2
— 11
a3
— 100
a4
— 101
Эта схема представляет собой префиксный код, являющийся кодом Хаффмана. Самый часто встречающийся в потоке символ a1
мы будем кодировать самым коротким словом 0, а самый редко встречающийся a4
длинным словом 101.
Для последовательности из 100 символов, в которой символ a1
встретится 50 раз, символ a2
— 24 раза, символ a3
— 15 раз, а символ a4
— 11 раз, данный код позволит получить последовательность из 176 бит (
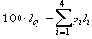
Доказательства теоремы, а также того, что построенная схема действительно задает код Хаффмана, смотри в [10].
Как стало понятно из изложенного выше, классический алгоритм Хаффмана требует записи в файл таблицы соответствия кодируемых символов и кодирующих цепочек.
На практике используются его разновидности. Так, в некоторых случаях резонно либо использовать постоянную таблицу, либо строить ее “адаптивно”, т.е. в процессе архивации/разархивации. Эти приемы избавляют нас от двух проходов по изображению и необходимости хранения таблицы вместе с файлом. Кодирование с фиксированной таблицей применяется в качестве последнего этапа архивации в JPEG и в рассмотренном ниже алгоритме CCITT Group 3.
Характеристики классического алгоритма Хаффмана:
Коэффициенты компрессии: 8, 1,5, 1 (Лучший, средний, худший коэффициенты).
Класс изображений: Практически не применяется к изображениям в чистом виде. Обычно используется как один из этапов компрессии в более сложных схемах.
Симметричность: 2 (за счет того, что требует двух проходов по массиву сжимаемых данных).
Характерные особенности: Единственный алгоритм, который не увеличивает размера исходных данных в худшем случае (если не считать необходимости хранить таблицу перекодировки вместе с файлом).
<
| Алгоритм Хаффмана с фиксированной таблицей CCITTGroup 3 Близкая модификация алгоритма используется при сжатии черно-белых изображений (один бит на пиксел). Полное название данного алгоритма CCITT Group 3. Это означает, что данный алгоритм был предложен третьей группой по стандартизации Международного Консультационного Комитета по Телеграфии и Телефонии (Consultative Committee International Telegraph and Telephone). Последовательности подряд идущих черных и белых точек в нем заменяются числом, равным их количеству. А этот ряд, уже в свою очередь, сжимается по Хаффману с фиксированной таблицей. Определение: Набор идущих подряд точек изображения одного цвета называется серией.Длина этого набора точек называется длиной серии. В таблице, приведенной ниже, заданы два вида кодов: Коды завершения серий — заданы с 0 до 63 с шагом 1. Составные (дополнительные) коды — заданы с 64 до 2560 с шагом 64. Каждая строка изображения сжимается независимо. Мы считаем, что в нашем изображении существенно преобладает белый цвет, и все строки изображения начинаются с белой точки. Если строка начинается с черной точки, то мы считаем, что строка начинается белой серией с длиной 0. Например, последовательность длин серий 0, 3, 556, 10, ... означает, что в этой строке изображения идут сначала 3 черных точки, затем 556 белых, затем 10 черных и т.д. На практике в тех случаях, когда в изображении преобладает черный цвет, мы инвертируем изображение перед компрессией и записываем информацию об этом в заголовок файла. Алгоритм компрессии выглядит так: for(по всем строкам изображения) { Преобразуем строку в набор длин серий; for(по всем сериям) { if(серия белая) { L= длина серии; while(L > 2623) { // 2623=2560+63 L=L-2560; ЗаписатьБелыйКодДля(2560); } if(L > 63) { L2=МаксимальныйСостКодМеньшеL(L); L=L-L2; ЗаписатьБелыйКодДля(L2); } ЗаписатьБелыйКодДля(L); //Это всегда код завершения } else { [Код аналогичный белой серии, с той разницей, что записываются черные коды] } } // Окончание строки изображения } Поскольку черные и белые серии чередуются, то реально код для белой и код для черной серии будут работать попеременно. В терминах регулярных выражений мы получим для каждой строки нашего изображения (достаточно длинной, начинающейся с белой точки) выходной битовый поток вида: ((<Б-2560>)*[<Б-сст.>]<Б-зв.>(<Ч-2560>)*[<Ч-сст.>]<Ч-зв.>)+ [(<Б-2560>)*[<Б-сст.>]<Б-зв.>] Где ()* — повтор 0 или более раз, ()+.— повтор 1 или более раз, [] — включение 1 или 0 раз. Для приведенного ранее примера: 0, 3, 556, 10... алгоритм сформирует следующий код: <Б-0><Ч-3><Б-512><Б-44><Ч-10>, или, согласно таблице, 001101011001100101001011010000100 (разные коды в потоке выделены для удобства). Этот код обладает свойством префиксных кодов и легко может быть свернут обратно в последовательность длин серий. Легко подсчитать, что для приведенной строки в 569 бит мы получили код длиной в 33 бита, т.е. коэффициент сжатия составляет примерно 17 раз. Вопрос к экзамену: Во сколько раз увеличится размер файла в худшем случае? Почему? (Приведенный в характеристиках алгоритма ответ не является полным, поскольку возможны большие значения худшего коэффициента сжатия. Найдите их.) |
 Изображение, для которого очень выгодно применение алгоритма CCITT-3. (Большие области заполнены одним цветом). |
 Изображение, для которого менее выгодно применение алгоритма CCITT-3. (Меньше областей, заполненных одним цветом. Много коротких “черных” и “белых” серий). |
|
Заметим, что единственное “сложное” выражение в нашем алгоритме: L2=МаксимальныйДопКодМеньшеL(L) — на практике работает очень просто: L2=(L>>6)*64, где >> — побитовый сдвиг L влево на 6 битов (можно сделать то же самое за одну побитовую операцию & — логическое И). Упражнение: Дана строка изображения, записанная в виде длин серий — 442, 2, 56, 3, 23, 3, 104, 1, 94, 1, 231, размером 120 байт ((442+2+..+231)/8). Подсчитать коэффициент компрессии этой строки алгоритмом CCITT Group 3. Приведенные ниже таблицы построены с помощью классического алгоритма Хаффмана (отдельно для длин черных и белых серий). Значения вероятностей появления для конкретных длин серий были получены путем анализа большого количества факсимильных изображений. Таблица кодов завершения: |
| Длина серии |
Код белой подстроки |
Код черной подстроки |
Длина серии |
Код белой подстроки |
Код черной подстроки |
|
| 0 | 00110101 | 0000110111 | 32 | 00011011 | 000001101010 | |
| 1 | 00111 | 010 | 33 | 00010010 | 000001101011 | |
| 2 | 0111 | 11 | 34 | 00010011 | 000011010010 | |
| 3 | 1000 | 10 | 35 | 00010100 | 000011010011 | |
| 4 | 1011 | 011 | 36 | 00010101 | 000011010100 | |
| 5 | 1100 | 0011 | 37 | 00010110 | 000011010101 | |
| 6 | 1110 | 0010 | 38 | 00010111 | 000011010110 | |
| 7 | 1111 | 00011 | 39 | 00101000 | 000011010111 | |
| 8 | 10011 | 000101 | 40 | 00101001 | 000001101100 | |
| 9 | 10100 | 000100 | 41 | 00101010 | 000001101101 | |
| 10 | 00111 | 0000100 | 42 | 00101011 | 000011011010 | |
| 11 | 01000 | 0000101 | 43 | 00101100 | 000011011011 | |
| 12 | 001000 | 0000111 | 44 | 00101101 | 000001010100 | |
| 13 | 000011 | 00000100 | 45 | 00000100 | 000001010101 | |
| 14 | 110100 | 00000111 | 46 | 00000101 | 000001010110 | |
| 15 | 110101 | 000011000 | 47 | 00001010 | 000001010111 | |
| 16 | 101010 | 0000010111 | 48 | 00001011 | 000001100100 | |
| 17 | 101011 | 0000011000 | 49 | 01010010 | 000001100101 | |
| 18 | 0100111 | 0000001000 | 50 | 01010011 | 000001010010 | |
| 19 | 0001100 | 00001100111 | 51 | 01010100 | 000001010011 | |
| 20 | 0001000 | 00001101000 | 52 | 01010101 | 000000100100 | |
| 21 | 0010111 | 00001101100 | 53 | 00100100 | 000000110111 | |
| 22 | 0000011 | 00000110111 | 54 | 00100101 | 000000111000 | |
| 23 | 0000100 | 00000101000 | 55 | 01011000 | 000000100111 | |
| 24 | 0101000 | 00000010111 | 56 | 01011001 | 000000101000 | |
| 25 | 0101011 | 00000011000 | 57 | 01011010 | 000001011000 | |
| 26 | 0010011 | 000011001010 | 58 | 01011011 | 000001011001 | |
| 27 | 0100100 | 000011001011 | 59 | 01001010 | 000000101011 | |
| 28 | 0011000 | 000011001100 | 60 | 01001011 | 000000101100 | |
| 29 | 00000010 | 000011001101 | 61 | 00110010 | 000001011010 | |
| 30 | 00000011 | 000001101000 | 62 | 00110011 | 000001100110 | |
| 31 | 00011010 | 000001101001 | 63 | 00110100 | 000001100111 |
Таблица составных кодов:
| Длина серии |
Код белой подстроки |
Код черной подстроки |
Длина серии |
Код белой подстроки |
Код черной подстроки |
|
| 64 | 11011 | 0000001111 | 1344 | 011011010 | 0000001010011 | |
| 128 | 10010 | 000011001000 | 1408 | 011011011 | 0000001010100 | |
| 192 | 01011 | 000011001001 | 1472 | 010011000 | 0000001010101 | |
| 256 | 0110111 | 000001011011 | 1536 | 010011001 | 0000001011010 | |
| 320 | 00110110 | 000000110011 | 1600 | 010011010 | 0000001011011 | |
| 384 | 00110111 | 000000110100 | 1664 | 011000 | 0000001100100 | |
| 448 | 01100100 | 000000110101 | 1728 | 010011011 | 0000001100101 | |
| 512 | 01100101 | 0000001101100 | 1792 | 00000001000 |
совп. с белой |
|
| 576 | 01101000 | 0000001101101 | 1856 | 00000001100 |
— // — |
|
| 640 | 01100111 | 0000001001010 | 1920 | 00000001101 |
— // — |
|
| 704 | 011001100 | 0000001001011 | 1984 | 000000010010 |
— // — |
|
| 768 | 011001101 | 0000001001100 | 2048 | 000000010011 |
— // — |
|
| 832 | 011010010 | 0000001001101 | 2112 | 000000010100 |
— // — |
|
| 896 | 011010011 | 0000001110010 | 2176 | 000000010101 |
— // — |
|
| 960 | 011010100 | 0000001110011 | 2240 | 000000010110 |
— // — |
|
| 1024 | 011010101 | 0000001110100 | 2304 | 000000010111 |
— // — |
|
| 1088 | 011010110 | 0000001110101 | 2368 | 000000011100 |
— // — |
|
| 1152 | 011010111 | 0000001110110 | 2432 | 000000011101 |
— // — |
|
| 1216 | 011011000 | 0000001110111 | 2496 | 000000011110 |
— // — |
|
| 1280 | 011011001 | 0000001010010 | 2560 | 000000011111 |
— // — |
| Если в одном столбце встретятся два числа с одинаковым префиксом, то это опечатка. Этот алгоритм реализован в формате TIFF. Характеристики алгоритма CCITT Group 3 Коэффициенты компрессии: лучший коэффициент стремится в пределе к 213.(3), средний 2, в худшем случае увеличивает файл в 5 раз. Класс изображений: Двуцветные черно-белые изображения, в которых преобладают большие пространства, заполненные белым цветом. Симметричность: Близка к 1. Характерные особенности: Данный алгоритм чрезвычайно прост в реализации, быстр и может быть легко реализован аппаратно. Алгоритм JPEGJPEG — один из самых новых и достаточно мощных алгоритмов. Практически он является стандартом де-факто для полноцветных изображений [1]. Оперирует алгоритм областями 8х8, на которых яркость и цвет меняются сравнительно плавно. Вследствие этого, при разложении матрицы такой области в двойной ряд по косинусам (см. формулы ниже) значимыми оказываются только первые коэффициенты. Таким образом, сжатие в JPEG осуществляется за счет плавности изменения цветов в изображении. Алгоритм разработан группой экспертов в области фотографии специально для сжатия 24-битных изображений. JPEG — Joint Photographic Expert Group — подразделение в рамках ISO — Международной организации по стандартизации. Название алгоритма читается ['jei'peg]. В целом алгоритм основан на дискретном косинусоидальном преобразовании (в дальнейшем ДКП), применяемом к матрице изображения для получения некоторой новой матрицы коэффициентов. Для получения исходного изображения применяется обратное преобразование. ДКП раскладывает изображение по амплитудам некоторых частот. Таким образом, при преобразовании мы получаем матрицу, в которой многие коэффициенты либо близки, либо равны нулю. Кроме того, благодаря несовершенству человеческого зрения, можно аппроксимировать коэффициенты более грубо без заметной потери качества изображения. Для этого используется квантование коэффициентов (quantization). В самом простом случае — это арифметический побитовый сдвиг вправо. При этом преобразовании теряется часть информации, но могут достигаться большие коэффициенты сжатия. Как работает алгоритм Итак, рассмотрим алгоритм подробнее. Пусть мы сжимаем 24-битное изображение. Шаг 1. Переводим изображение из цветового пространства RGB, с компонентами, отвечающими за красную (Red), зеленую (Green) и синюю (Blue) составляющие цвета точки, в цветовое пространство YCrCb (иногда называют YUV). В нем Y — яркостная составляющая, а Cr, Cb — компоненты, отвечающие за цвет (хроматический красный и хроматический синий). За счет того, что человеческий глаз менее чувствителен к цвету, чем к яркости, появляется возможность архивировать массивы для Cr и Cb компонент с большими потерями и, соответственно, большими коэффициентами сжатия. Подобное преобразование уже давно используется в телевидении. На сигналы, отвечающие за цвет, там выделяется более узкая полоса частот. Упрощенно перевод из цветового пространства RGB в цветовое пространство YCrCb можно представить с помощью матрицы перехода: 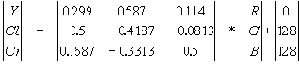 Обратное преобразование осуществляется умножением вектора YUV на обратную матрицу. 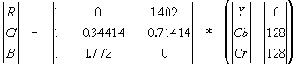 Шаг 2. Разбиваем исходное изображение на матрицы 8х8. Формируем из каждой три рабочие матрицы ДКП — по 8 бит отдельно для каждой компоненты. При больших коэффициентах сжатия этот шаг может выполняться чуть сложнее. Изображение делится по компоненте Y — как и в первом случае, а для компонент Cr и Cb матрицы набираются через строчку и через столбец. Т.е. из исходной матрицы размером 16x16 получается только одна рабочая матрица ДКП. При этом, как нетрудно заметить, мы теряем 3/4 полезной информации о цветовых составляющих изображения и получаем сразу сжатие в два раза. Мы можем поступать так благодаря работе в пространстве YCrCb. На результирующем RGB изображении, как показала практика, это сказывается несильно. Шаг 3. Применяем ДКП к каждой рабочей матрице. При этом мы получаем матрицу, в которой коэффициенты в левом верхнем углу соответствуют низкочастотной составляющей изображения, а в правом нижнем — высокочастотной. В упрощенном виде это преобразование можно представить так: 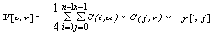 где 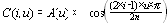 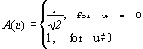 Шаг 4. Производим квантование. В принципе, это просто деление рабочей матрицы на матрицу квантования поэлементно. Для каждой компоненты (Y, U и V), в общем случае, задается своя матрица квантования q[u,v] (далее МК). 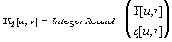 На этом шаге осуществляется управление степенью сжатия, и происходят самые большие потери. Понятно, что, задавая МК с большими коэффициентами, мы получим больше нулей и, следовательно, большую степень сжатия. В стандарт JPEG включены рекомендованные МК, построенные опытным путем. Матрицы для большего или меньшего коэффициентов сжатия получают путем умножения исходной матрицы на некоторое число gamma. С квантованием связаны и специфические эффекты алгоритма. При больших значениях коэффициента gamma потери в низких частотах могут быть настолько велики, что изображение распадется на квадраты 8х8. Потери в высоких частотах могут проявиться в так называемом “эффекте Гиббса”, когда вокруг контуров с резким переходом цвета образуется своеобразный “нимб”. Шаг 5. Переводим матрицу 8x8 в 64-элементный вектор при помощи “зигзаг”-сканирования, т.е. берем элементы с индексами (0,0), (0,1), (1,0), (2,0)...  Таким образом, в начале вектора мы получаем коэффициенты матрицы, соответствующие низким частотам, а в конце — высоким. Шаг 6. Свертываем вектор с помощью алгоритма группового кодирования. При этом получаем пары типа (пропустить, число), где “пропустить” является счетчиком пропускаемых нулей, а “число” — значение, которое необходимо поставить в следующую ячейку. Так, вектор 42 3 0 0 0 -2 0 0 0 0 1 ... будет свернут в пары (0,42) (0,3) (3,-2) (4,1) ... . Шаг 7. Свертываем получившиеся пары кодированием по Хаффману с фиксированной таблицей. Процесс восстановления изображения в этом алгоритме полностью симметричен. Метод позволяет сжимать некоторые изображения в 10-15 раз без серьезных потерь. 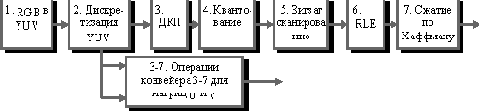
Существенными положительными сторонами алгоритма является то, что: Задается степень сжатия. Выходное цветное изображение может иметь 24 бита на точку. Отрицательными сторонами алгоритма является то, что: При повышении степени сжатия изображение распадается на отдельные квадраты (8x8). Это связано с тем, что происходят большие потери в низких частотах при квантовании, и восстановить исходные данные становится невозможно. Проявляется эффект Гиббса — ореолы по границам резких переходов цветов. Как уже говорилось, стандартизован JPEG относительно недавно — в 1991 году. Но уже тогда существовали алгоритмы, сжимающие сильнее при меньших потерях качества. Дело в том, что действия разработчиков стандарта были ограничены мощностью существовавшей на тот момент техники. То есть даже на персональном компьютере алгоритм должен был работать меньше минуты на среднем изображении, а его аппаратная реализация должна быть относительно простой и дешевой. Алгоритм должен был быть симметричным (время разархивации примерно равно времени архивации). Последнее требование сделало возможным появление таких игрушек, как цифровые фотоаппараты — устройства, размером с небольшую видеокамеру, снимающие 24-битовые фотографии на 10-20 Мб флэш карту с интерфейсом PCMCIA. Потом эта карта вставляется в разъем на вашем лэптопе и соответствующая программа позволяет считать изображения. Не правда ли, если бы алгоритм был несимметричен, было бы неприятно долго ждать, пока аппарат “перезарядится” — сожмет изображение. Не очень приятным свойством JPEG является также то, что нередко горизонтальные и вертикальные полосы на дисплее абсолютно не видны и могут проявиться только при печати в виде муарового узора. Он возникает при наложении наклонного растра печати на горизонтальные и вертикальные полосы изображения. Из-за этих сюрпризов JPEG не рекомендуется активно использовать в полиграфии, задавая высокие коэффициенты. Однако при архивации изображений, предназначенных для просмотра человеком, он на данный момент незаменим. Широкое применение JPEG долгое время сдерживалось, пожалуй, лишь тем, что он оперирует 24-битными изображениями. Поэтому для того, чтобы с приемлемым качеством посмотреть картинку на обычном мониторе в 256-цветной палитре, требовалось применение соответствующих алгоритмов и, следовательно, определенное время. В приложениях, ориентированных на придирчивого пользователя, таких, например, как игры, подобные задержки неприемлемы. Кроме того, если имеющиеся у вас изображения, допустим, в 8-битном формате GIF перевести в 24-битный JPEG, а потом обратно в GIF для просмотра, то потеря качества произойдет дважды при обоих преобразованиях. Тем не менее, выигрыш в размерах архивов зачастую настолько велик (в 3-20 раз!), а потери качества настолько малы, что хранение изображений в JPEG оказывается очень эффективным. Несколько слов необходимо сказать о модификациях этого алгоритма. Хотя JPEG и является стандартом ISO, формат его файлов не был зафиксирован. Пользуясь этим, производители создают свои, несовместимые между собой форматы, и, следовательно, могут изменить алгоритм. Так, внутренние таблицы алгоритма, рекомендованные ISO, заменяются ими на свои собственные. Кроме того, легкая неразбериха присутствует при задании степени потерь. Например, при тестировании выясняется, что “отличное” качество, “100%” и “10 баллов” дают существенно различающиеся картинки. При этом, кстати, “100%” качества не означают сжатие без потерь. Встречаются также варианты JPEG для специфических приложений. Как стандарт ISO JPEG начинает все шире использоваться при обмене изображениями в компьютерных сетях. Поддерживается алгоритм JPEG в форматах Quick Time, PostScript Level 2, Tiff 6.0 и, на данный момент, занимает видное место в системах мультимедиа. Характеристики алгоритма JPEG: Коэффициенты компрессии: 2-200 (Задается пользователем). Класс изображений: Полноцветные 24 битные изображения или изображения в градациях серого без резких переходов цветов (фотографии). Симметричность: 1 Характерные особенности: В некоторых случаях, алгоритм создает “ореол” вокруг резких горизонтальных и вертикальных границ в изображении (эффект Гиббса). Кроме того, при высокой степени сжатия изображение распадается на блоки 8х8 пикселов. |
Алгоритм LZWНазвание алгоритм получил по первым буквам фамилий его разработчиков — Lempel, Ziv и Welch. Сжатие в нем, в отличие от RLE, осуществляется уже за счет одинаковых цепочек байт. Алгоритм LZ Существует довольно большое семейство LZ-подобных алгоритмов, различающихся, например, методом поиска повторяющихся цепочек. Один из достаточно простых вариантов этого алгоритма, например, предполагает, что во входном потоке идет либо пара <счетчик, смещение относительно текущей позиции>, либо просто <счетчик> “пропускаемых” байт и сами значения байтов (как во втором варианте алгоритма RLE). При разархивации для пары <счетчик, смещение> копируются <счетчик> байт из выходного массива, полученного в результате разархивации, на <смещение> байт раньше, а <счетчик> (т.е. число равное счетчику) значений “пропускаемых” байт просто копируются в выходной массив из входного потока. Данный алгоритм является несимметричным по времени, поскольку требует полного перебора буфера при поиске одинаковых подстрок. В результате нам сложно задать большой буфер из-за резкого возрастания времени компрессии. Однако потенциально построение алгоритма, в котором на <счетчик> и на <смещение> будет выделено по 2 байта (старший бит старшего байта счетчика — признак повтора строки / копирования потока), даст нам возможность сжимать все повторяющиеся подстроки размером до 32Кб в буфере размером 64Кб. 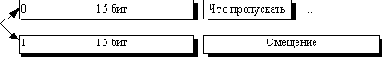 При этом мы получим увеличение размера файла в худшем случае на 32770/32768 (в двух байтах записано, что нужно переписать в выходной поток следующие 215 байт), что совсем неплохо. Максимальный коэффициент сжатия составит в пределе 8192 раза. В пределе, поскольку максимальное сжатие мы получаем, превращая 32Кб буфера в 4 байта, а буфер такого размера мы накопим не сразу. Однако, минимальная подстрока, для которой нам выгодно проводить сжатие, должна состоять в общем случае минимум из 5 байт, что и определяет малую ценность данного алгоритма. К достоинствам LZ можно отнести чрезвычайную простоту алгоритма декомпрессии. Упражнение: Предложите другой вариант алгоритма LZ, в котором на пару <счетчик, смещение> будет выделено 3 байта, и подсчитайте основные характеристики своего алгоритма. Алгоритм LZW Рассматриваемый нами ниже вариант алгоритма будет использовать дерево для представления и хранения цепочек. Очевидно, что это достаточно сильное ограничение на вид цепочек, и далеко не все одинаковые подцепочки в нашем изображении будут использованы при сжатии. Однако в предлагаемом алгоритме выгодно сжимать даже цепочки, состоящие из 2 байт. Процесс сжатия выглядит достаточно просто. Мы считываем последовательно символы входного потока и проверяем, есть ли в созданной нами таблице строк такая строка. Если строка есть, то мы считываем следующий символ, а если строки нет, то мы заносим в поток код для предыдущей найденной строки, заносим строку в таблицу и начинаем поиск снова. Функция InitTable() очищает таблицу и помещает в нее все строки единичной длины. InitTable();
Как говорилось выше, функция InitTable() инициализирует таблицу строк так, чтобы она содержала все возможные строки, состоящие из одного символа. Например, если мы сжимаем байтовые данные, то таких строк в таблице будет 256 (“0”, “1”, ... , “255”). Для кода очистки (ClearCode) и кода конца информации (CodeEndOfInformation) зарезервированы значения 256 и 257. В рассматриваемом варианте алгоритма используется 12-битный код, и, соответственно, под коды для строк нам остаются значения от 258 до 4095. Добавляемые строки записываются в таблицу последовательно, при этом индекс строки в таблице становится ее кодом. Функция ReadNextByte() читает символ из файла. Функция WriteCode() записывает код (не равный по размеру байту) в выходной файл. Функция AddStringToTable() добавляет новую строку в таблицу, приписывая ей код. Кроме того, в данной функции происходит обработка ситуации переполнения таблицы. В этом случае в поток записывается код предыдущей найденной строки и код очистки, после чего таблица очищается функцией InitTable(). Функция CodeForString() находит строку в таблице и выдает код этой строки. Пример: Пусть мы сжимаем последовательность 45, 55, 55, 151, 55, 55, 55. Тогда, согласно изложенному выше алгоритму, мы поместим в выходной поток сначала код очистки <256>, потом добавим к изначально пустой строке “45” и проверим, есть ли строка “45” в таблице. Поскольку мы при инициализации занесли в таблицу все строки из одного символа, то строка “45” есть в таблице. Далее мы читаем следующий символ 55 из входного потока и проверяем, есть ли строка “45, 55” в таблице. Такой строки в таблице пока нет. Мы заносим в таблицу строку “45, 55” (с первым свободным кодом 258) и записываем в поток код <45>. Можно коротко представить архивацию так: “45” — есть в таблице; “45, 55” — нет. Добавляем в таблицу <258>“45, 55”. В поток: <45>; “55, 55” — нет. В таблицу: <259>“55, 55”. В поток: <55>; “55, 151” — нет. В таблицу: <260>“55, 151”. В поток: <55>; “151, 55” — нет. В таблицу: <261>“151, 55”. В поток: <151>; “55, 55” — есть в таблице; “55, 55, 55” — нет. В таблицу: “55, 55, 55” <262>. В поток: <259>; Последовательность кодов для данного примера, попадающих в выходной поток: <256>, <45>, <55>, <55>, <151>, <259>. Особенность LZW заключается в том, что для декомпрессии нам не надо сохранять таблицу строк в файл для распаковки. Алгоритм построен таким образом, что мы в состоянии восстановить таблицу строк, пользуясь только потоком кодов. Мы знаем, что для каждого кода надо добавлять в таблицу строку, состоящую из уже присутствующей там строки и символа, с которого начинается следующая строка в потоке. 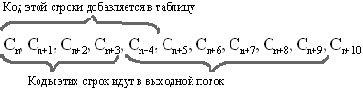 Алгоритм декомпрессии, осуществляющий эту операцию, выглядит следующим образом: code=File.ReadCode();
Здесь функция ReadCode() читает очередной код из декомпрессируемого файла. Функция InitTable() выполняет те же действия, что и при компрессии, т.е. очищает таблицу и заносит в нее все строки из одного символа. Функция FirstChar() выдает нам первый символ строки. Функция StrFromTable() выдает строку из таблицы по коду. Функция AddStringToTable() добавляет новую строку в таблицу (присваивая ей первый свободный код). Функция WriteString() записывает строку в файл. Замечание 1. Как вы могли заметить, записываемые в поток коды постепенно возрастают. До тех пор, пока в таблице не появится, например, в первый раз код 512, все коды будут меньше 512. Кроме того, при компрессии и при декомпрессии коды в таблице добавляются при обработке одного и того же символа, т.е. это происходит “синхронно”. Мы можем воспользоваться этим свойством алгоритма для того, чтобы повысить степень компрессии. Пока в таблицу не добавлен 512 символ, мы будем писать в выходной битовый поток коды из 9 бит, а сразу при добавлении 512 — коды из 10 бит. Соответственно декомпрессор также должен будет воспринимать все коды входного потока 9-битными до момента добавления в таблицу кода 512, после чего будет воспринимать все входные коды как 10-битные. Аналогично мы будем поступать при добавлении в таблицу кодов 1024 и 2048. Данный прием позволяет примерно на 15% поднять степень компрессии: 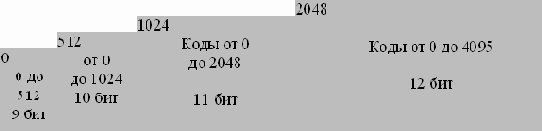 Замечание 2. При сжатии изображения нам важно обеспечить быстроту поиска строк в таблице. Мы можем воспользоваться тем, что каждая следующая подстрока на один символ длиннее предыдущей, кроме того, предыдущая строка уже была нами найдена в таблице. Следовательно, достаточно создать список ссылок на строки, начинающиеся с данной подстроки, как весь процесс поиска в таблице сведется к поиску в строках, содержащихся в списке для предыдущей строки. Понятно, что такая операция может быть проведена очень быстро. Заметим также, что реально нам достаточно хранить в таблице только пару <код предыдущей подстроки, добавленный символ>. Этой информации вполне достаточно для работы алгоритма. Таким образом, массив от 0 до 4095 с элементами <код предыдущей подстроки; добавленный символ; список ссылок на строки, начинающиеся с этой строки> решает поставленную задачу поиска, хотя и очень медленно. На практике для хранения таблицы используется такое же быстрое, как в случае списков, но более компактное по памяти решение — хэш-таблица. Таблица состоит из 8192 (213) элементов. Каждый элемент содержит <код предыдущей подстроки; добавленный символ; код этой строки>. Ключ для поиска длиной в 20 бит формируется с использованием двух первых элементов, хранимых в таблице как одно число (key). Младшие 12 бит этого числа отданы под код, а следующие 8 бит под значение символа. В качестве хэш-функции при этом используется: Index(key)= ((key >> 12) ^ key) & 8191; Где >> — побитовый сдвиг вправо (key >> 12 — мы получаем значение символа), ^ — логическая операция побитового исключающего ИЛИ, & логическое побитовое И. Таким образом, за считанное количество сравнений мы получаем искомый код или сообщение, что такого кода в таблице нет. Подсчитаем лучший и худший коэффициенты компрессии для данного алгоритма. Лучший коэффициент, очевидно, будет получен для цепочки одинаковых байт большой длины (т.е. для 8-битного изображения, все точки которого имеют, для определенности, цвет 0). При этом в 258 строку таблицы мы запишем строку “0, 0”, в 259 — “0, 0, 0”, ... в 4095 — строку из 3839 (=4095-256) нулей. При этом в поток попадет (проверьте по алгоритму!) 3840 кодов, включая код очистки. Следовательно, посчитав сумму арифметической прогрессии от 2 до 3839 (т.е. длину сжатой цепочки) и поделив ее на 3840*12/8 (в поток записываются 12-битные коды), мы получим лучший коэффициент компрессии. Упражнение: Вычислить точное значение лучшего коэффициента компрессии. Более сложное задание: вычислить тот же коэффициент с учетом замечания 1. Худший коэффициент будет получен, если мы ни разу не встретим подстроку, которая уже есть в таблице (в ней не должно встретиться ни одной одинаковой пары символов). Упражнение: Составить алгоритм генерации таких цепочек. Попробовать сжать полученный таким образом файл стандартными архиваторами (zip, arj, gz). Если вы получите сжатие, значит алгоритм генерации написан неправильно. В случае, если мы постоянно будем встречать новую подстроку, мы запишем в выходной поток 3840 кодов, которым будет соответствовать строка из 3838 символов. Без учета замечания 1 это составит увеличение файла почти в 1.5 раза. LZW реализован в форматах GIF и TIFF. Характеристики алгоритма LZW: Коэффициенты компрессии: Примерно 1000, 4, 5/7 (Лучший, средний, худший коэффициенты). Сжатие в 1000 раз достигается только на одноцветных изображениях размером кратным примерно 7 Мб. Класс изображений: Ориентирован LZW на 8-битные изображения, построенные на компьютере. Сжимает за счет одинаковых подцепочек в потоке. Симметричность: Почти симметричен, при условии оптимальной реализации операции поиска строки в таблице. Характерные особенности: Ситуация, когда алгоритм увеличивает изображение, встречается крайне редко. LZW универсален — именно его варианты используются в обычных архиваторах. |
Алгоритм RLEПервый вариант алгоритма Данный алгоритм необычайно прост в реализации. Групповое кодирование — от английского Run Length Encoding (RLE) — один из самых старых и самых простых алгоритмов архивации графики. Изображение в нем (как и в нескольких алгоритмах, описанных ниже) вытягивается в цепочку байт по строкам растра. Само сжатие в RLE происходит за счет того, что в исходном изображении встречаются цепочки одинаковых байт. Замена их на пары <счетчик повторений, значение> уменьшает избыточность данных. Алгоритм декомпрессии при этом выглядит так: Initialization(...);
В данном алгоритме признаком счетчика (counter) служат единицы в двух верхних битах считанного файла:  Соответственно оставшиеся 6 бит расходуются на счетчик, который может принимать значения от 1 до 64. Строку из 64 повторяющихся байтов мы превращаем в два байта, т.е. сожмем в 32 раза. Упражнение: Составьте алгоритм компрессии для первого варианта алгоритма RLE. Алгоритм рассчитан на деловую графику — изображения с большими областями повторяющегося цвета. Ситуация, когда файл увеличивается, для этого простого алгоритма не так уж редка. Ее можно легко получить, применяя групповое кодирование к обработанным цветным фотографиям. Для того, чтобы увеличить изображение в два раза, его надо применить к изображению, в котором значения всех пикселов больше двоичного 11000000 и подряд попарно не повторяются. Вопрос к экзамену: Предложите два-три примера “плохих” изображений для алгоритма RLE. Объясните, почему размер сжатого файла больше размера исходного файла. Данный алгоритм реализован в формате PCX. См. пример в приложении. Второй вариант алгоритма Второй вариант этого алгоритма имеет больший максимальный коэффициент архивации и меньше увеличивает в размерах исходный файл. Алгоритм декомпрессии для него выглядит так: Initialization(...);
Признаком повтора в данном алгоритме является единица в старшем разряде соответствующего байта:  Как можно легко подсчитать, в лучшем случае этот алгоритм сжимает файл в 64 раза (а не в 32 раза, как в предыдущем варианте), в худшем увеличивает на 1/128. Средние показатели степени компрессии данного алгоритма находятся на уровне показателей первого варианта. Упражнение: Составьте алгоритм компрессии для второго варианта алгоритма RLE. Похожие схемы компрессии использованы в качестве одного из алгоритмов, поддерживаемых форматом TIFF, а также в формате TGA. Характеристики алгоритма RLE: Коэффициенты компрессии: Первый вариант: 32, 2, 0,5. Второй вариант: 64, 3, 128/129. (Лучший, средний, худший коэффициенты) Класс изображений: Ориентирован алгоритм на изображения с небольшим количеством цветов: деловую и научную графику. Симметричность: Примерно единица. Характерные особенности: К положительным сторонам алгоритма, пожалуй, можно отнести только то, что он не требует дополнительной памяти при архивации и разархивации, а также быстро работает. Интересная особенность группового кодирования состоит в том, что степень архивации для некоторых изображений может быть существенно повышена всего лишь за счет изменения порядка цветов в палитре изображения. |
Алгоритмы архивации без потерьАлгоритм RLE Алгоритм LZW Алгоритм Хаффмана JBIG Lossless JPEG Заключение Контрольные вопросы к разделу Алгоритм RLE Алгоритм LZW Алгоритм Хаффмана JBIG Lossless JPEG Заключение Контрольные вопросы к разделу Алгоритмы архивации с потерямиПроблемы алгоритмов архивации с потерями Алгоритм JPEG Фрактальный алгоритм Рекурсивный (волновой) алгоритм Заключение Контрольные вопросы к разделу Проблемы алгоритмов архивации с потерями Алгоритм JPEG Фрактальный алгоритм Рекурсивный (волновой) алгоритм Заключение Контрольные вопросы к разделу Архивация 16-цветного изображения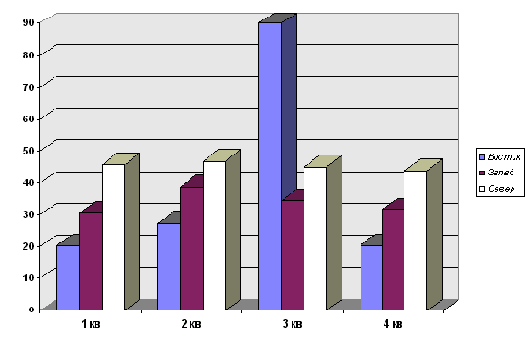 Изображение 619х405х16 цвета 125.350 байт |
Ниже приведена степень компрессии изображений в зависимости от применяемого алгоритма:
Не смотря на то, что данное изображение относится к классу изображений, на которые ориентирован алгоритм RLE (отвечает критериям “хорошего” изображения для алгоритма RLE), заметно лучшие результаты для него дает более универсальный алгоритм LZW. Архивация двуцветного изображения |
 |
 |
|
Изображение 1000х1000х2 цвета 125.000 байт |
То же изображение с внесенными в него помехами |
| Алгоритм RLE | Алгоритм LZW | CCITT Group 3 |
CCITT Group 4 |
|
| Без помех | 10,6 (TIFF-CCITT RLE) 6,6 (TIFF-PackBits) 4,9 (PCX) 2,99 (BMP) 2,9 (TGA) |
12 (TIFF-LZW) 10,1 (GIF) |
9,5 (TIFF) | 31,2 (TIFF) |
| С помехами |
5 (TIFF-CCITT RLE) 2,49 (TIFF-PackBits) 2,26 (PCX) 1,7 (TGA) 1,69 (BMP) |
5,4 (TIFF-LZW) 5,1 (GIF) |
4,7 (TIFF) | 5,12 (TIFF) |
| Выводы, которые можно сделать, анализируя данную таблицу: Лучшие результаты показал алгоритм, оптимизированный для этого класса изображений CCITT Group 4 и модификация универсального алгоритма LZW. Даже в рамках одного алгоритма велик разброс значений алгоритма компрессии. Заметим, что реализации RLE и LZW для TIFF показали заметно лучшие результаты, чем в других форматах. Более того, во всех колонках все варианты алгоритмов сжатия реализованные в формате TIFF лидируют. Архивация изображения в градациях серого |
Архивация полноцветного изображения

Изображение 320х320хRGB — 307.200 байт
Ниже приведена степень компрессии изображений в зависимости от применяемого алгоритма:
<
| Алгоритм RLE | Алгоритм LZW | Алгоритм JPEG | |
| Первое изображение |
1,046 (TGA) 1,037 (TIFF-PackBits) |
1,12 (TIFF-LZW) 4,65 (GIF) С потерями! Изображение в 256 цветах |
47,2 (JPEG q=10) 23,98 (JPEG q=30) 11,5 (JPEG q=100) |
| Выводы, которые можно сделать, анализируя таблицу: Алгоритм JPEG при визуально намного меньших потерях (q=100) сжал изображение в 2 раза сильнее, чем LZW с использованием перевода в изображение с палитрой. Алгоритм LZW, примененный к 24-битному изображению практически на дает сжатия. Минимальное сжатие, полученное алгоритмом RLE можно объяснить тем, что изображение в нижней части имеет сравнительно большую область однородного белого цвета (полученную после обработки изображения). Архивация полноцветного изображения в 100 раз |
320х320хRGB — 307.200 байт |
 Сжатие в 100 раз JPEG (3.08Кb) |
 Сжатие в 100 раз (3.04Кb) фрактальным алгоритмом |
 Сжатие в 100 раз (3.04Кb) wavelet алгоритмом |
|
(ИЗОБРАЖЕНИЯ ДЛЯ WWW-варианта лекций ПЕРЕВЕДЕНЫ В JPEG хоть и максимальным качеством, но с потерями) На данном примере хорошо видно, что при высоких степенях компрессии алгоритм JPEG оказывается полностью неконкурентоспособным. Также хорошо видны артефакты, вносимые в изображение всеми алгоритмами. Качество изображения для фрактального алгоритма визуально несколько ниже, однако для него не используется постобработка изображения (достаточно “разумное” сглаживание), из-за которого у волнового алгоритма размываются мелкие детали изображения. |
Фрактальный алгоритмИдея метода Фрактальная архивация основана на том, что мы представляем изображение в более компактной форме — с помощью коэффициентов системы итерируемых функций (Iterated Function System — далее по тексту как IFS). Прежде, чем рассматривать сам процесс архивации, разберем, как IFS строит изображение, т.е. процесс декомпрессии. Строго говоря, IFS представляет собой набор трехмерных аффинных преобразований, в нашем случае переводящих одно изображение в другое. Преобразованию подвергаются точки в трехмерном пространстве (х_координата, у_координата, яркость). Наиболее наглядно этот процесс продемонстрировал Барнсли в своей книге “Fractal Image Compression”. Там введено понятие Фотокопировальной Машины, состоящей из экрана, на котором изображена исходная картинка, и системы линз, проецирующих изображение на другой экран: Линзы могут проецировать часть изображения произвольной формы в любое другое место нового изображения. Области, в которые проецируются изображения, не пересекаются. Линза может менять яркость и уменьшать контрастность. Линза может зеркально отражать и поворачивать свой фрагмент изображения. Линза должна масштабировать (уменьшать)свой фрагмент изображения. 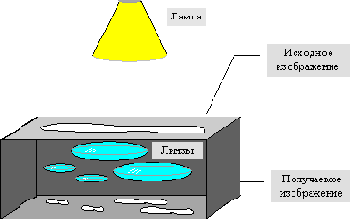 Расставляя линзы и меняя их характеристики, мы можем управлять получаемым изображением. Одна итерация работы Машины заключается в том, что по исходному изображению с помощью проектирования строится новое, после чего новое берется в качестве исходного. Утверждается, что в процессе итераций мы получим изображение, которое перестанет изменяться. Оно будет зависеть только от расположения и характеристик линз, и не будет зависеть от исходной картинки. Это изображение называется “неподвижной точкой” или аттрактором данной IFS. Соответствующая теория гарантирует наличие ровно одной неподвижной точки для каждой IFS. Поскольку отображение линз является сжимающим, каждая линза в явном виде задает самоподобные области в нашем изображении. Благодаря самоподобию мы получаем сложную структуру изображения при любом увеличении. Таким образом, интуитивно понятно, что система итерируемых функций задает фрактал (нестрого — самоподобный математический объект). Наиболее известны два изображения, полученных с помощью IFS: “треугольник Серпинского” и “папоротник Барнсли”. “Треугольник Серпинского” задается тремя, а “папоротник Барнсли” четырьмя аффинными преобразованиями (или, в нашей терминологии, “линзами”). Каждое преобразование кодируется буквально считанными байтами, в то время как изображение, построенное с их помощью, может занимать и несколько мегабайт.  Упражнение: Укажите в изображении 4 области, объединение которых покрывало бы все изображение, и каждая из которых была бы подобна всему изображению (не забывайте о стебле папоротника). Из вышесказанного становится понятно, как работает архиватор, и почему ему требуется так много времени. Фактически, фрактальная компрессия — это поиск самоподобных областей в изображении и определение для них параметров аффинных преобразований. |


| В худшем случае, если не будет применяться оптимизирующий алгоритм, потребуется перебор и сравнение всех возможных фрагментов изображения разного размера. Даже для небольших изображений при учете дискретности мы получим астрономическое число перебираемых вариантов. Причем, даже резкое сужение классов преобразований, например, за счет масштабирования только в определенное количество раз, не дает заметного выигрыша во времени. Кроме того, при этом теряется качество изображения. Подавляющее большинство исследований в области фрактальной компрессии сейчас направлены на уменьшение времени архивации, необходимого для получения качественного изображения. Далее приводятся основные определения и теоремы, на которых базируется фрактальная компрессия. Этот материал более детально и с доказательствами рассматривается в [3] и в [4]. Определение. Преобразование 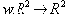 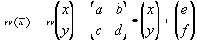 где a, b, c, d, e, f действительные числа и 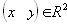 называется двумерным аффинным преобразованием. Определение. Преобразование 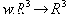 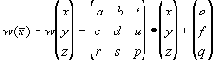 где a, b, c, d, e, f, p, q, r, s, t, u действительные числа и 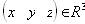 называется трехмерным аффинным преобразованием. Определение. Пусть  — преобразование в пространстве Х. Точка 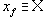 такая, что 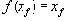 неподвижной точкой (аттрактором) преобразования. Определение. Преобразование 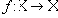 в метрическом пространстве (Х, d) называется сжимающим, если существует число s: 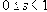 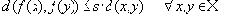 Замечание: Формально мы можем использовать любое сжимающее отображение при фрактальной компрессии, но реально используются лишь трехмерные аффинные преобразования с достаточно сильными ограничениями на коэффициенты. Теорема. (О сжимающем преобразовании) Пусть в полном метрическом пространстве (Х, d). Тогда существует в точности одна неподвижная точка 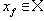 этого преобразования, и для любой точки 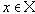 последовательность 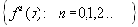 сходится к  Более общая формулировка этой теоремы гарантирует нам сходимость. Определение. Изображением называется функция S, определенная на единичном квадрате и принимающая значения от 0 до 1 или 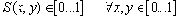 Пусть трехмерное аффинное преобразование 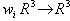 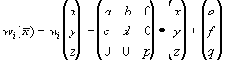 и определено на компактном подмножестве  декартова квадрата [0..1]x[0..1]. Тогда оно переведет часть поверхности S в область  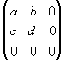 При этом, если интерпретировать значение S как яркость соответствующих точек, она уменьшится в p раз (преобразование обязано быть сжимающим) и изменится на сдвиг q. Определение. Конечная совокупность W сжимающих трехмерных аффинных преобразований  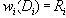 и  Системе итерируемых функций однозначно сопоставляется неподвижная точка — изображение. Таким образом, процесс компрессии заключается в поиске коэффициентов системы, а процесс декомпрессии — в проведении итераций системы до стабилизации полученного изображения (неподвижной точки IFS). На практике бывает достаточно 7-16 итераций. Области в дальнейшем будут именоваться ранговыми, а области — доменными. Построение алгоритма Как уже стало очевидным из изложенного выше, основной задачей при компрессии фрактальным алгоритмом является нахождение соответствующих аффинных преобразований. В самом общем случае мы можем переводить любые по размеру и форме области изображения, однако в этом случае получается астрономическое число перебираемых вариантов разных фрагментов, которое невозможно обработать на текущий момент даже на суперкомпьютере. В учебном варианте алгоритма, изложенном далее, сделаны следующие ограничения на области: Все области являются квадратами со сторонами, параллельными сторонам изображения. Это ограничение достаточно жесткое. Фактически мы собираемся аппроксимировать все многообразие геометрических фигур лишь квадратами. При переводе доменной области в ранговую уменьшение размеров производится ровно в два раза. Это существенно упрощает как компрессор, так и декомпрессор, т.к. задача масштабирования небольших областей является нетривиальной. Все доменные блоки — квадраты и имеют фиксированный размер. Изображение равномерной сеткой разбивается на набор доменных блоков. Доменные области берутся “через точку” и по Х, и по Y, что сразу уменьшает перебор в 4 раза. При переводе доменной области в ранговую поворот куба возможен только на 00, 900, 1800 или 2700. Также допускается зеркальное отражение. Общее число возможных преобразований (считая пустое) — 8. Масштабирование (сжатие) по вертикали (яркости) осуществляется в фиксированное число раз — в 0,75.  Эти ограничения позволяют: Построить алгоритм, для которого требуется сравнительно малое число операций даже на достаточно больших изображениях. Очень компактно представить данные для записи в файл. Нам требуется на каждое аффинное преобразование в IFS: два числа для того, чтобы задать смещение доменного блока. Если мы ограничим входные изображения размером 512х512, то достаточно будет по 8 бит на каждое число. три бита для того, чтобы задать преобразование симметрии при переводе доменного блока в ранговый. 7-9 бит для того, чтобы задать сдвиг по яркости при переводе. Информацию о размере блоков можно хранить в заголовке файла. Таким образом, мы затратили менее 4 байт на одно аффинное преобразование. В зависимости от того, каков размер блока, можно высчитать, сколько блоков будет в изображении. Таким образом, мы можем получить оценку степени компрессии. Например, для файла в градациях серого 256 цветов 512х512 пикселов при размере блока 8 пикселов аффинных преобразований будет 4096 (512/8x512/8). На каждое потребуется 3.5 байта. Следовательно, если исходный файл занимал 262144 (512х512) байт (без учета заголовка), то файл с коэффициентами будет занимать 14336 байт. Коэффициент архивации — 18 раз. При этом мы не учитываем, что файл с коэффициентами тоже может обладать избыточностью и архивироваться методом архивации без потерь, например LZW. Отрицательные стороны предложенных ограничений: Поскольку все области являются квадратами, невозможно воспользоваться подобием объектов, по форме далеких от квадратов (которые встречаются в реальных изображениях достаточно часто.) Аналогично мы не сможем воспользоваться подобием объектов в изображении, коэффициент подобия между которыми сильно отличается от 2. Алгоритм не сможет воспользоваться подобием объектов в изображении, угол между которыми не кратен 900. Такова плата за скорость компрессии и за простоту упаковки коэффициентов в файл. Сам алгоритм упаковки сводится к перебору всех доменных блоков и подбору для каждого соответствующего ему рангового блока. Ниже приводится схема этого алгоритма. for (all range blocks) { min_distance = MaximumDistance; Rij = image->CopyBlock(i,j); for (all domain blocks) { // С поворотами и отр. current=Координаты тек. преобразования; D=image->CopyBlock(current); current_distance = Rij.L2distance(D); if(current_distance < min_distance) { // Если коэффициенты best хуже: min_distance = current_distance; best = current; } } //Next range Save_Coefficients_to_file(best); } //Next domain Как видно из приведенного алгоритма, для каждого рангового блока делаем его проверку со всеми возможными доменными блоками (в том числе с прошедшими преобразование симметрии), находим вариант с наименьшей мерой L2 (наименьшим среднеквадратичным отклонением) и сохраняем коэффициенты этого преобразования в файл. Коэффициенты — это (1) координаты найденного блока, (2) число от 0 до 7, характеризующее преобразование симметрии (поворот, отражение блока), и (3) сдвиг по яркости для этой пары блоков. Сдвиг по яркости вычисляется как: 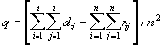 где rij — значения пикселов рангового блока (R), а dij — значения пикселов доменного блока (D). При этом мера считается как: 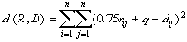 Мы не вычисляем квадратного корня из L2 меры и не делим ее на n, поскольку данные преобразования монотонны и не помешают нам найти экстремум, однако мы сможем выполнять на две операции меньше для каждого блока. Посчитаем количество операций, необходимых нам для сжатия изображения в градациях серого 256 цветов 512х512 пикселов при размере блока 8 пикселов:
Схема алгоритма декомпрессии изображений Декомпрессия алгоритма фрактального сжатия чрезвычайно проста. Необходимо провести несколько итераций трехмерных аффинных преобразований, коэффициенты которых были получены на этапе компрессии. В качестве начального может быть взято абсолютно любое изображение (например, абсолютно черное), поскольку соответствующий математический аппарат гарантирует нам сходимость последовательности изображений, получаемых в ходе итераций IFS, к неподвижному изображению (близкому к исходному). Обычно для этого достаточно 16 итераций. Прочитаем из файла коэффициенты всех блоков; Создадим черное изображение нужного размера; Until(изображение не станет неподвижным){ For(every range (R)){ D=image->CopyBlock(D_coord_for_R); For(every pixel(i,j) in the block{ Rij = 0.75Dij + oR; } //Next pixel } //Next block }//Until end Поскольку мы записывали коэффициенты для блоков Rij (которые, как мы оговорили, в нашем частном случае являются квадратами одинакового размера) последовательно, то получается, что мы последовательно заполняем изображение по квадратам сетки разбиения использованием аффинного преобразования. Как можно подсчитать, количество операций на один пиксел изображения в градациях серого при восстановлении необычайно мало (N операций “+”, 1 операций “* ”, где N — количество итераций, т.е. 7-16). Благодаря этому, декомпрессия изображений для фрактального алгоритма проходит быстрее декомпрессии, например, для алгоритма JPEG, в котором на точку приходится (при оптимальной реализации операций обратного ДКП и квантования) 64 операции “+” и 64 операции “? ” (без учета шагов RLE и кодирования по Хаффману!). При этом для фрактального алгоритма умножение происходит на рациональное число, одно для каждого блока. Это означает, что мы можем, во-первых, использовать целочисленную рациональную арифметику, которая существенно быстрее арифметики с плавающей точкой. Во-вторых, умножение вектора на число — более простая и быстрая операция, часто закладываемая в архитектуру процессора (процессоры SGI, Intel MMX...), чем скалярное произведение двух векторов, необходимое в случае JPEG. Для полноцветного изображения ситуация качественно не изменяется, поскольку перевод в другое цветовое пространство используют оба алгоритма. Оценка потерь и способы их регулирования При кратком изложении упрощенного варианта алгоритма были пропущены многие важные вопросы. Например, что делать, если алгоритм не может подобрать для какого-либо фрагмента изображения подобный ему? Достаточно очевидное решение — разбить этот фрагмент на более мелкие, и попытаться поискать для них. В то же время понятно, что эту процедуру нельзя повторять до бесконечности, иначе количество необходимых преобразований станет так велико, что алгоритм перестанет быть алгоритмом компрессии. Следовательно, мы допускаем потери в какой-то части изображения. Для фрактального алгоритма компрессии, как и для других алгоритмов сжатия с потерями, очень важны механизмы, с помощью которых можно будет регулировать степень сжатия и степень потерь. К настоящему времени разработан достаточно большой набор таких методов. Во-первых, можно ограничить количество аффинных преобразований, заведомо обеспечив степень сжатия не ниже фиксированной величины. Во-вторых, можно потребовать, чтобы в ситуации, когда разница между обрабатываемым фрагментом и наилучшим его приближением будет выше определенного порогового значения, этот фрагмент дробился обязательно (для него обязательно заводится несколько “линз”). В-третьих, можно запретить дробить фрагменты размером меньше, допустим, четырех точек. Изменяя пороговые значения и приоритет этих условий, мы будем очень гибко управлять коэффициентом компрессии изображения в диапазоне от побитового соответствия до любой степени сжатия. Заметим, что эта гибкость будет гораздо выше, чем у ближайшего “конкурента” — алгоритма JPEG. Характеристики фрактального алгоритма : Коэффициенты компрессии: 2-2000 (Задается пользователем). Класс изображений: Полноцветные 24 битные изображения или изображения в градациях серого без резких переходов цветов (фотографии). Желательно, чтобы области большей значимости (для восприятия) были более контрастными и резкими, а области меньшей значимости — неконтрастными и размытыми. Симметричность: 100-100000 Характерные особенности: Может свободно масштабировать изображение при разархивации, увеличивая его в 2-4 раза без появления “лестничного эффекта”. При увеличении степени компрессии появляется “блочный” эффект на границах блоков в изображении. |
Информация на английском:Сборник из 130 статей по фрактальному сжатию избражений
Wavelet Resources
Data Compression Reference Center
Глобальный набор ссылок по сжатию
|
Информация на русском:Страница лаборатории компьютерной графики ВМиК МГУ
Страница этого пособия в МГУ
Страница этого пособия у меня
Словарные определения для терминов области сжатия изображений
Неплохой набор материалов и ссылок по сжатию Максима Захорова
Два курса по ВЕЙВЛЕТ-АНАЛИЗУ
MPEG
http://nle.hardware.ru/teoria/mpeg/mpeg_faq.htm Статическая графика (начальные сведения о изображениях)
Вселенная фракталов
Графические форматы Web
Достаточно интересная подборка статей со сжатию
Энциклопедия графических форматов
Домашние странички авторов ньюсгруппы comp.compression
JBIGАлгоритм разработан группой экспертов ISO (Joint Bi-level Experts Group) специально для сжатия однобитных черно-белых изображений [5]. Например, факсов или отсканированных документов. В принципе, может применяться и к 2-х, и к 4-х битовым картинкам. При этом алгоритм разбивает их на отдельные битовые плоскости. JBIG позволяет управлять такими параметрами, как порядок разбиения изображения на битовые плоскости, ширина полос в изображении, уровни масштабирования. Последняя возможность позволяет легко ориентироваться в базе больших по размерам изображений, просматривая сначала их уменьшенные копии. Настраивая эти параметры, можно использовать описанный выше эффект “огрубленного изображения” при получении изображения по сети или по любому другому каналу, пропускная способность которого мала по сравнению с возможностями процессора. Распаковываться изображение на экране будет постепенно, как бы медленно “проявляясь”. При этом человек начинает анализировать картинку задолго до конца процесса разархивации. Алгоритм построен на базе Q-кодировщика [6], патентом на который владеет IBM. Q-кодер, так же как и алгоритм Хаффмана, использует для чаще появляющихся символов короткие цепочки, а для реже появляющихся — длинные. Однако, в отличие от него, в алгоритме используются и последовательности символов. Классы изображенийСтатические растровые изображения представляют собой двумерный массив чисел. Элементы этого массива называют пикселами (от английского pixel — picture element). Все изображения можно подразделить на две группы — с палитрой и без нее. У изображений с палитрой в пикселе хранится число — индекс в некотором одномерном векторе цветов, называемом палитрой. Чаще всего встречаются палитры из 16 и 256 цветов. Изображения без палитры бывают в какой-либо системе цветопредставления и в градациях серого (grayscale). Для последних значение каждого пиксела интерпретируется как яркость соответствующей точки. Встречаются изображения с 2, 16 и 256 уровнями серого. Одна из интересных практических задач заключается в приведении цветного или черно-белого изображения к двум градациям яркости, например, для печати на лазерном принтере. При использовании некой системы цветопредставления каждый пиксел представляет собой запись (структуру), полями которой являются компоненты цвета. Самой распространенной является система RGB, в которой цвет представлен значениями интенсивности красной (R), зеленой (G) и синей (B) компонент. Существуют и другие системы цветопредставления, такие, как CMYK, CIE XYZccir60-1 и т.п. Ниже мы увидим, как используются цветовые модели при сжатии изображений с потерями. Для того, чтобы корректнее оценивать степень сжатия, нужно ввести понятие класса изображений. Под классом будет пониматься некая совокупность изображений, применение к которым алгоритма архивации дает качественно одинаковые результаты. Например, для одного класса алгоритм дает очень высокую степень сжатия, для другого — почти не сжимает, для третьего — увеличивает файл в размере. (Известно, что многие алгоритмы в худшем случае увеличивают файл.) Рассмотрим следующие примеры неформального определения классов изображений: Класс 1. Изображения с небольшим количеством цветов (4-16) и большими областями, заполненными одним цветом. Плавные переходы цветов отсутствуют. Примеры: деловая графика — гистограммы, диаграммы, графики и т.п. Класс 2. Изображения, с плавными переходами цветов, построенные на компьютере. Примеры: графика презентаций, эскизные модели в САПР, изображения, построенные по методу Гуро. Класс 3. Фотореалистичные изображения. Пример: отсканированные фотографии. Класс 4. Фотореалистичные изображения с наложением деловой графики. Пример: реклама. Развивая данную классификацию, в качестве отдельных классов могут быть предложены некачественно отсканированные в 256 градаций серого цвета страницы книг или растровые изображения топографических карт. (Заметим, что этот класс не тождественен классу 4). Формально являясь 8- или 24-битными, они несут даже не растровую, а чисто векторную информацию. Отдельные классы могут образовывать и совсем специфичные изображения: рентгеновские снимки или фотографии в профиль и фас из электронного досье. Достаточно сложной и интересной задачей является поиск наилучшего алгоритма для конкретного класса изображений. Итог: Нет смысла говорить о том, что какой-то алгоритм сжатия лучше другого, если мы не обозначили классы изображений, на которых сравниваются наши алгоритмы. |
Классы приложенийПримеры приложений, использующих алгоритмы компрессии графики Рассмотрим следующую простую классификацию приложений, использующих алгоритмы компрессии: Класс 1. Характеризуются высокими требованиями ко времени архивации и разархивации. Нередко требуется просмотр уменьшенной копии изображения и поиск в базе данных изображений. Примеры: Издательские системы в широком смысле этого слова. Причем как готовящие качественные публикации (журналы) с заведомо высоким качеством изображений и использованием алгоритмов архивации без потерь, так и готовящие газеты, и информационные узлы в WWW, где есть возможность оперировать изображениями меньшего качества и использовать алгоритмы сжатия с потерями. В подобных системах приходится иметь дело с полноцветными изображениями самого разного размера (от 640х480 — формат цифрового фотоаппарата, до 3000х2000) и с большими двуцветными изображениями. Поскольку иллюстрации занимают львиную долю от общего объема материала в документе, проблема хранения стоит очень остро. Проблемы также создает большая разнородность иллюстраций (приходится использовать универсальные алгоритмы). Единственное, что можно сказать заранее, это то, что будут преобладать фотореалистичные изображения и деловая графика. Класс 2. Характеризуется высокими требованиями к степени архивации и времени разархивации. Время архивации роли не играет. Иногда подобные приложения также требуют от алгоритма компрессии легкости масштабирования изображения под конкретное разрешение монитора у пользователя. Пример: Справочники и энциклопедии на CD-ROM. С появлением большого количества компьютеров, оснащенных этим приводом (в США — у 50% машин), достаточно быстро сформировался рынок программ, выпускаемых на лазерных дисках. Несмотря на то, что емкость одного диска довольно велика (примерно 650 Мб), ее, как правило, не хватает. При создании энциклопедий и игр большую часть диска занимают статические изображения и видео. Таким образом, для этого класса приложений актуальность приобретают существенно асимметричные по времени алгоритмы (симметричность по времени — отношение времени компрессии ко времени декомпрессии). Класс 3. Характеризуется очень высокими требованиями к степени архивации. Приложение клиента получает от сервера информацию по сети. Пример: Новая быстро развивающаяся система “Всемирная информационная паутина” — WWW. В этой гипертекстовой системе достаточно активно используются иллюстрации. При оформлении информационных или рекламных страниц хочется сделать их более яркими и красочными, что естественно сказывается на размере изображений. Больше всего при этом страдают пользователи, подключенные к сети с помощью медленных каналов связи. Если страница WWW перенасыщена графикой, то ожидание ее полного появления на экране может затянуться. Поскольку при этом нагрузка на процессор мала, то здесь могут найти применение эффективно сжимающие сложные алгоритмы со сравнительно большим временем разархивации. Кроме того, мы можем видоизменить алгоритм и формат данных так, чтобы просматривать огрубленное изображение файла до его полного получения. Можно привести множество более узких классов приложений. Так, свое применение машинная графика находит и в различных информационных системах. Например, уже становится привычным исследовать ультразвуковые и рентгеновские снимки не на бумаге, а на экране монитора. Постепенно в электронный вид переводят и истории болезней. Понятно, что хранить эти материалы логичнее в единой картотеке. При этом без использования специальных алгоритмов большую часть архивов займут фотографии. Поэтому при создании эффективных алгоритмов решения этой задачи нужно учесть специфику рентгеновских снимков — преобладание размытых участков. В геоинформационных системах — при хранении аэрофотоснимков местности — специфическими проблемами являются большой размер изображения и необходимость выборки лишь части изображения по требованию. Кроме того, может потребоваться масштабирование. Это неизбежно накладывает свои ограничения на алгоритм компрессии. В электронных картотеках и досье различных служб для изображений характерно подобие между фотографиями в профиль, и подобие между фотографиями в фас, которое также необходимо учитывать при создании алгоритма архивации. Подобие между фотографиями наблюдается и в любых других специализированных справочниках. В качестве примера можно привести энциклопедии птиц или цветов. Итог: Нет смысла говорить о том, что какой-то конкретный алгоритм компрессии лучше другого, если мы не обозначили класс приложений, для которого мы эти алгоритмы собираемся сравнивать. Требования приложений к алгоритмам компрессии В предыдущем разделе мы определили, какие приложения являются потребителями алгоритмов архивации изображений. Однако заметим, что приложение определяет характер использования изображений (либо большое количество изображений хранится и используется, либо изображения скачиваются по сети, либо изображения велики по размерам, и нам необходима возможность получения лишь части...). Характер использования изображений задает степень важности следующих ниже противоречивых требований к алгоритму: Высокая степень компрессии. Заметим, что далеко не для всех приложений актуальна высокая степень компрессии. Кроме того, некоторые алгоритмы дают лучшее соотношение качества к размеру файла при высоких степенях компрессии, однако проигрывают другим алгоритмам при низких степенях. Высокое качество изображений. Выполнение этого требования напрямую противоречит выполнению предыдущего... Высокая скорость компрессии. Это требование для некоторых алгоритмов с потерей информации является взаимоисключающим с первыми двумя. Интуитивно понятно, что чем больше времени мы будем анализировать изображение, пытаясь получить наивысшую степень компрессии, тем лучше будет результат. И, соответственно, чем меньше мы времени потратим на компрессию (анализ), тем ниже будет качество изображения и больше его размер. Высокая скорость декомпрессии. Достаточно универсальное требование, актуальное для многих приложений. Однако можно привести примеры приложений, где время декомпрессии далеко не критично. Масштабирование изображений. Данное требование подразумевает легкость изменения размеров изображения до размеров окна активного приложения. Дело в том, что одни алгоритмы позволяют легко масштабировать изображение прямо во время декомпрессии, в то время как другие не только не позволяют легко масштабировать, но и увеличивают вероятность появления неприятных артефактов после применения стандартных алгоритмов масштабирования к декомпрессированному изображению. Например, можно привести пример “плохого” изображения для алгоритма JPEG — это изображение с достаточно мелким регулярным рисунком (пиджак в мелкую клетку). Характер вносимых алгоритмом JPEG искажений таков, что уменьшение или увеличение изображения может дать неприятные эффекты. Возможность показать огрубленное изображение (низкого разрешения), использовав только начало файла. Данная возможность актуальна для различного рода сетевых приложений, где перекачивание изображений может занять достаточно большое время, и желательно, получив начало файла, корректно показать preview. Заметим, что примитивная реализация указанного требования путем записывания в начало изображения его уменьшенной копии заметно ухудшит степень компрессии. Устойчивость к ошибкам. Данное требование означает локальность нарушений в изображении при порче или потере фрагмента передаваемого файла. Данная возможность используется при широковещании (broadcasting — передача по многим адресам) изображений по сети, то есть в тех случаях, когда невозможно использовать протокол передачи, повторно запрашивающий данные у сервера при ошибках. Например, если передается видеоряд, то было бы неправильно использовать алгоритм, у которого сбой приводил бы к прекращению правильного показа всех последующих кадров. Данное требование противоречит высокой степени архивации, поскольку интуитивно понятно, что мы должны вводить в поток избыточную информацию. Однако для разных алгоритмов объем этой избыточной информации может существенно отличаться. Учет специфики изображения. Более высокая степень архивации для класса изображений, которые статистически чаще будут применяться в нашем приложении. В предыдущих разделах это требование уже обсуждалось. Редактируемость. Под редактируемостью понимается минимальная степень ухудшения качества изображения при его повторном сохранении после редактирования. Многие алгоритмы с потерей информации могут существенно испортить изображение за несколько итераций редактирования. Небольшая стоимость аппаратной реализации.Эффективность программной реализации. Данные требования к алгоритму реально предъявляют не только производители игровых приставок, но и производители многих информационных систем. Так, декомпрессор фрактального алгоритма очень эффективно и коротко реализуется с использованием технологии MMX и распараллеливания вычислений, а сжатие по стандарту CCITT Group 3 легко реализуется аппаратно. Очевидно, что для конкретной задачи нам будут очень важны одни требования и менее важны (и даже абсолютно безразличны) другие. Итог: На практике для каждой задачи мы можем сформулировать набор приоритетов из требований, изложенных выше, который и определит наиболее подходящий в наших условиях алгоритм (либо набор алгоритмов) для ее решения. Контрольные вопросы к разделуКакие параметры надо определить, прежде чем сравнивать два алгоритма компрессии? Почему некорректно сравнивать временные параметры реализаций алгоритмов компрессии, оптимально реализованных на разных компьютерах? Приведите примеры ситуаций, когда архитектура компьютера дает преимущества тому или иному алгоритму. Предложите пример своего класса изображений. Какими свойствами изображений мы можем пользоваться, создавая алгоритм компрессии? Приведите примеры. Что такое редактируемость? Назовите основные требования приложений к алгоритмам компрессии. Что такое симметричность? Предложите пример своего класса приложений. Приведите примеры аппаратной реализации алгоритма сжатия изображений (повседневные и достаточно новые). Почему высокая скорость компрессии, высокое качество изображений и высокая степень компрессии взаимно противоречивы? Покажите противоречивость каждой пары условий.  |
|
В чем разница между алгоритмами с потерей информации и без потери информации? Приведите примеры мер потери информации и опишите их недостатки. За счет чего сжимает изображения алгоритм JPEG? В чем заключается идея фрактального алгоритма компрессии? В чем заключается идея рекурсивного (волнового) сжатия? Можно ли применять прием перевода в другое цветовое пространство алгоритма JPEG в других алгоритмах компрессии?
|
Критерии сравнения алгоритмовЗаметим, что характеристики алгоритма относительно некоторых требований приложений, сформулированные выше, зависят от конкретных условий, в которые будет поставлен алгоритм. Так, степень компрессии зависит от того, на каком классе изображений алгоритм тестируется. Аналогично, скорость компрессии нередко зависит от того, на какой платформе реализован алгоритм. Преимущество одному алгоритму перед другим может дать, например, возможность использования в вычислениях алгоритма технологий нижнего уровня, типа MMX, а это возможно далеко не для всех алгоритмов. Так, JPEG существенно выигрывает от применения технологии MMX, а LZW нет. Кроме того, нам придется учитывать, что некоторые алгоритмы распараллеливаются легко, а некоторые нет. Таким образом, невозможно составить универсальное сравнительное описание известных алгоритмов. Это можно сделать только для типовых классов приложений при условии использования типовых алгоритмов на типовых платформах. Однако такие данные необычайно быстро устаревают. Так, например, еще три года назад, в 1994, интерес к показу огрубленного изображения, используя только начало файла (требование 6), был чисто абстрактным. Реально эта возможность практически нигде не требовалась и класс приложений, использующих данную технологию, был крайне невелик. С взрывным распространением Internet, который характеризуется передачей изображений по сравнительно медленным каналам связи, использование Interlaced GIF (алгоритм LZW) и Progressive JPEG (вариант алгоритма JPEG), реализующих эту возможность, резко возросло. То, что новый алгоритм (например, wavelet) поддерживает такую возможность, существеннейший плюс для него сегодня. В то же время мы можем рассмотреть такое редкое на сегодня требование, как устойчивость к ошибкам. Можно предположить, что в скором времени (через 5-10 лет) с распространением широковещания в сети Internet для его обеспечения будут использоваться именно алгоритмы, устойчивые к ошибкам, даже не рассматриваемые в сегодняшних статьях и обзорах. Со всеми сделанными выше оговорками, выделим несколько наиболее важных для нас критериев сравнения алгоритмов компрессии, которые и будем использовать в дальнейшем. Как легко заметить, мы будем обсуждать меньше критериев, чем было сформулировано выше. Это позволит избежать лишних деталей при кратком изложении данного курса. Худший, средний и лучший коэффициенты сжатия. То есть доля, на которую возрастет изображение, если исходные данные будут наихудшими; некий среднестатистический коэффициент для того класса изображений, на который ориентирован алгоритм; и, наконец, лучший коэффициент. Последний необходим лишь теоретически, поскольку показывает степень сжатия наилучшего (как правило, абсолютно черного) изображения, иногда фиксированного размера. Класс изображений, на который ориентирован алгоритм. Иногда указано также, почему на других классах изображений получаются худшие результаты. Симметричность. Отношение характеристики алгоритма кодирования к аналогичной характеристике при декодировании. Характеризует ресурсоемкость процессов кодирования и декодирования. Для нас наиболее важной является симметричность по времени: отношение времени кодирования ко времени декодирования. Иногда нам потребуется симметричность по памяти. Есть ли потери качества? И если есть, то за счет чего изменяется коэффициент архивации? Дело в том, что у большинства алгоритмов сжатия с потерей информации существует возможность изменения коэффициента сжатия. Характерные особенности алгоритма и изображений, к которым его применяют. Здесь могут указываться наиболее важные для алгоритма свойства, которые могут стать определяющими при его выборе. Используя данные критерии, приступим к рассмотрению алгоритмов архивации изображений. Прежде, чем непосредственно начать разговор об алгоритмах, хотелось бы сделать оговорку. Один и тот же алгоритм часто можно реализовать разными способами. Многие известные алгоритмы, такие как RLE, LZW или JPEG, имеют десятки различающихся реализаций. Кроме того, у алгоритмов бывает несколько явных параметров, варьируя которые, можно изменять характеристики процессов архивации и разархивации. (См.примеры в разделе о форматах). При конкретной реализации эти параметры фиксируются, исходя из наиболее вероятных характеристик входных изображений, требований на экономию памяти, требований на время архивации и т.д. Поэтому у алгоритмов одного семейства лучший и худший коэффициенты могут отличаться, но качественно картина не изменится. ЛитератураЛитература по алгоритмам сжатия Литература по форматам изображений Литература по алгоритмам сжатия Литература по форматам изображений Литература по алгоритмам сжатия[1] G.K.Wallace “The JPEG still picture compression standard” // Communication of ACM. Volume 34. Number 4 April 1991. [2] B.Smith, L.Rowe “Algorithm for manipulating compressed images.” // Computer Graphics and applications. September 1993. [3] A.Jacquin “Fractal image coding based on a theory of iterated contractive image transformations” // Visual Comm. and Image Processing, vol. SPIE-1360, 1990. [4] Y.Fisher “Fractal image compression” // SigGraph-92. [5] “Progressive Bi-level Image Compression, Revision 4.1” // ISO/IEC JTC1/SC2/WG9, CD 11544, September 16, 1991. [6] W.B.Pennebaker J.L. Mitchell, G.G. Langdon, R.B. Arps, “An overview of the basic principles of the Q-coder adaptive binary arithmetic coder” // IBM Journal of research and development, Vol.32, No.6, November 1988, pp. 771-726. [7] D.A.Huffman “A method for the construction of minimum redundancy codes.” // Proc. of IRE val.40 1962 pp. 1098-1101. [8] Standardisation of Group 3 Facsimile apparatus for document transmission. CCITT Recommendations. Fascicle VII.2. T.4. 1980. [9] С.В.Яблонский “Введение в дискретную математику”. // М. “Наука”, 1986. Раздел “Теория кодирования”. [10] А.С.Климов “Форматы графических файлов”. // С.-Петербург, Изд. “ДиаСофт” 1995. [11] Д.С.Ватолин “Сжатие статических изображений” // Открытые системы сегодня. Номер 8 (29) Апрель 1995 [12] Д.С.Ватолин “MPEG - стандарт ISO на видео в системах мультимедиа” // Открытые системы. Номер 2. Лето 1995 [13] Д.С.Ватолин “Применение фракталов в машинной графике” // ComputerWorld-Россия. Номер 15. 12 декабря 1995 [14] Д.С.Ватолин “Тенденции развития алгоритмов архивации графики” // Открытые системы. Номер 4. Зима 1995 [15] Д.С.Ватолин “Фрактальное сжатие изображений” // ComputerWorld-Россия. Номер 6 (23). 20 февраля 1996 [16] Д.С.Ватолин “Использование графики в WWW” // ComputerWorld-Россия. Номер 15 (32). 23 апреля 1996 Литература по форматам изображений[17] А.С.Климов “Форматы графических файлов” // НИПФ “ДиаСофт Лтд”, 1995. [18] В.Ю.Романов “Популярные форматы файлов для хранения графических изображений на IBM PC” // Москва “Унитех”, 1992 [19] Том Сван “Форматы файлов Windows” // М. “Бином”, 1995 [20] E.Hamilton “JPEG File Interchange Format” // Version 1.2. September 1, 1992, San Jose CA: C-Cube Microsystems, Inc. [21] Aldus Corporation Developer’s Desk. “TIFF - Revision 6.0, Final”, June 3, 1992 |
Lossless JPEGЭтот алгоритм разработан группой экспертов в области фотографии (Joint Photographic Expert Group). В отличие от JBIG, Lossless JPEG ориентирован на полноцветные 24-битные или 8-битные в градациях серого изображения без палитры. Он представляет собой специальную реализацию JPEG без потерь. Коэффициенты сжатия: 20, 2, 1. Lossless JPEG рекомендуется применять в тех приложениях, где необходимо побитовое соответствие исходного и декомпрессированного изображений. Подробнее об алгоритме сжатия JPEG см. следующий раздел. Общие положения алгоритмов сжатия изображенийВведение Классы изображений Классы приложений Критерии сравнения алгоритмов Контрольные вопросы к разделу Введение Классы изображений Классы приложений Критерии сравнения алгоритмов Контрольные вопросы к разделу читается на факультете ВМиК МГУСпецкурс “Машинная графика-2” читается на факультете ВМиК МГУ уже более 10 лет. Являясь логическим продолжением общего курса “Машинная графика”, спецкурс более углубленно и детально рассматривает многие аспекты этой интересной области. В основную программу курса входит широкий круг вопросов: от графических примитивов до построения фотореалистичных изображения. В этом пособии детально рассматриваются алгоритмы сжатия изображений. При этом изложены классические, давно известные алгоритмы, такие как групповое кодирование, LZW сжатие, кодирование по Хаффману. Рассмотрен в рамках курса и сравнительно недавно появившийся алгоритм JPEG. Отдельное внимание уделено новым алгоритмам, таким как рекурсивное сжатие и фрактальное сжатие изображений. Рассмотрены вопросы корректного сравнения алгоритмов компрессии изображений и вопросы построения мер оценки потерь качества изображения. Сейчас в стадии подготовки находится гипертекстовый вариант этого пособия, который будет выложен на сайте нашей курса по адресу http://graphics.cs.msu.su/ Ю.М. Баяковский 13.11.98 |
Апплет, обеспечивающий фрактальную декомпрессиюАпплет написан Константином Храпченко в рамках дипломной работы, написан на языке Java и осуществляет распаковку изображения в реальном времени любым броузером, поддерживающим Java. Достоинства такого подхода: Сам код апплета занимает 24Кб и будучи скачан один раз позволяет распаковать любое количество изображений. Т.е. на изображениях большого размера мы получаем выигрыш сразу и значительный. Сам подход позволяет распаковывать изображения стандартным алгоримом на любой платформе, где поддерживается Java. Т.е. на Недостаком подхода является недостаточная на днный момент стандартизация Java-машин. Если вы не увидите изоражений то возможно у вас выключена поддержка Java, либо стоит попробовать другой броузер (апплет не является коммерческим и полномасштабного тестирования не проходил). И еще - зеркальное отражение изображения - это задокументированная ошибка. ;) |
Сжатия изображения 100
и 40
раз. Видна разница в качестве.
Хорошо видно, как меняется качество приближения частей изображения, при увеличении степени конмрессии. Характер этих скажений принципиально иной, чем, например, в алгоритме JPEG.
Таблицы сравнения алгоритмовАрхивация двуцветного изображения Архивация 16-цветного изображения Архивация изображения в градациях серого Архивация полноцветного изображения Архивация полноцветного изображения в 100 раз Проблемы алгоритмов архивации с потерямиПервыми для архивации изображений стали применяться привычные алгоритмы. Те, что использовались и используются в системах резервного копирования, при создании дистрибутивов и т.п. Эти алгоритмы архивировали информацию без изменений. Однако основной тенденцией в последнее время стало использование новых классов изображений. Старые алгоритмы перестали удовлетворять требованиям, предъявляемым к архивации. Многие изображения практически не сжимались, хотя “на взгляд” обладали явной избыточностью. Это привело к созданию нового типа алгоритмов — сжимающих с потерей информации. Как правило, коэффициент архивации и, следовательно, степень потерь качества в них можно задавать. При этом достигается компромисс между размером и качеством изображений. Одна из серьезных проблем машинной графики заключается в том, что до сих пор не найден адекватный критерий оценки потерь качества изображения. А теряется оно постоянно — при оцифровке, при переводе в ограниченную палитру цветов, при переводе в другую систему цветопредставления для печати, и, что для нас особенно важно, при архивации с потерями. Можно привести пример простого критерия: среднеквадратичное отклонение значений пикселов (L2 мера, или root mean square — RMS): 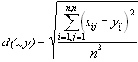 По нему изображение будет сильно испорчено при понижении яркости всего на 5% (глаз этого не заметит — у разных мониторов настройка яркости варьируется гораздо сильнее). В то же время изображения со “снегом” — резким изменением цвета отдельных точек, слабыми полосами или “муаром” будут признаны “почти не изменившимися” (Объясните, почему?). Свои неприятные стороны есть и у других критериев. Рассмотрим, например, максимальное отклонение:  Эта мера, как можно догадаться, крайне чувствительна к биению отдельных пикселов. Т.е. во всем изображении может существенно измениться только значение одного пиксела (что практически незаметно для глаза), однако согласно этой мере изображение будет сильно испорчено. Мера, которую сейчас используют на практике, называется мерой отношения сигнала к шуму (peak-to-peak signal-to-noise ratio — PSNR).  Данная мера, по сути, аналогична среднеквадратичному отклонению, однако пользоваться ей несколько удобнее за счет логарифмического масштаба шкалы. Ей присущи те же недостатки, что и среднеквадратичному отклонению. Лучше всего потери качества изображений оценивают наши глаза. Отличной считается архивация, при которой невозможно на глаз различить первоначальное и разархивированное изображения. Хорошей — когда сказать, какое из изображений подвергалось архивации, можно только сравнивая две находящихся рядом картинки. При дальнейшем увеличении степени сжатия, как правило, становятся заметны побочные эффекты, характерные для данного алгоритма. На практике, даже при отличном сохранении качества, в изображение могут быть внесены регулярные специфические изменения. Поэтому алгоритмы архивации с потерями не рекомендуется использовать при сжатии изображений, которые в дальнейшем собираются либо печатать с высоким качеством, либо обрабатывать программами распознавания образов. Неприятные эффекты с такими изображениями, как мы уже говорили, могут возникнуть даже при простом масштабировании изображения. |
Различия между форматом и алгоритмомДополнительный раздел Напоследок несколько замечаний относительно разницы в терминологии, путаницы при сравнении рейтингов алгоритмов и т.п. Посмотрите на краткий перечень форматов, достаточно часто используемых на PC, Apple и UNIX платформах: ADEX, Alpha Microsystems BMP, Autologic, AVHRR, Binary Information File (BIF), Calcomp CCRF, CALS, Core IDC, Cubicomp PictureMaker, Dr. Halo CUT, Encapsulated PostScript, ER Mapper Raster, Erdas LAN/GIS, First Publisher ART, GEM VDI Image File, GIF, GOES, Hitachi Raster Format, PCL, RTL, HP-48sx Graphic Object (GROB), HSI JPEG, HSI Raw, IFF/ILBM, Img Software Set, Jovian VI, JPEG/JFIF, Lumena CEL, Macintosh PICT/PICT2, MacPaint, MTV Ray Tracer Format, OS/2 Bitmap, PCPAINT/Pictor Page Format, PCX, PDS, Portable BitMap (PBM), QDV, QRT Raw, RIX, Scodl, Silicon Graphics Image, SPOT Image, Stork, Sun Icon, Sun Raster, Targa, TIFF, Utah Raster Toolkit Format, VITec, Vivid Format, Windows Bitmap, WordPerfect Graphic File, XBM, XPM, XWD. В оглавлении вы можете видеть список алгоритмов компрессии. Единственным совпадением оказывается JPEG, а это, согласитесь, не повод, чтобы повсеместно использовать слова “формат” и “алгоритм компрессии” как синонимы (что, увы, я постоянно наблюдаю). Между этими двумя множествами нет взаимно однозначного соответствия. Так, различные модификации алгоритма RLE реализованы в огромном количестве форматов. В том числе в TIFF, BMP, PCX. И, если в определенном формате какой-либо файл занимает много места, это не означает, что плох соответствующий алгоритм компрессии. Это означат, зачастую лишь то, что реализация алгоритма, использованная в этом формате, дает для данного изображения плохие результаты. Не более того. (См. примеры в приложении.) В то же время многие современные форматы поддерживают запись с использованием нескольких алгоритмов архивации либо без использования архивации. Например, формат TIFF 6.0 может сохранять изображения с использованием алгоритмов RLE-PackBits, RLE-CCITT, LZW, Хаффмана с фиксированной таблицей, JPEG, а может сохранять изображение без архивации. Аналогично форматы BMP и TGA позволяют сохранять файлы как с использованием алгоритма компрессии RLE (разных модификаций!), так и без использования оной. Вывод 1: Для многих форматов, говоря о размере файлов, необходимо указывать, использовался ли алгоритм компрессии и если использовался, то какой. Можно пополнить перечень ситуаций некорректного сравнения алгоритмов. При сохранении абсолютно черного изображения в формате 1000х1000х256 цветов в формате BMP без компрессии мы получаем, как и положено, файл размером чуть более 1000000 байт, а при сохранении с компрессией RLE, можно получить файл размером 64 байта. Это был бы превосходный результат — сжатие в 15 000 раз(!), если бы к нему имела отношение компрессия. Дело в том, что данный файл в 64 байта состоит только из заголовка изображения, в котором указаны все его данные. Несмотря на то, что такая короткая запись изображения стала возможна именно благодаря особенности реализации RLE в BMP, еще раз подчеркну, что в данном случае алгоритм компрессии даже не применялся. И то, что для абсолютно черного изображения 4000х4000х256 мы получаем коэффициент компрессии 250 тысяч раз, совсем не повод для продолжительных эмоций по поводу эффективности RLE. Кстати — данный результат возможен лишь при определенном положении цветов в палитре и далеко не на всех программах, которые умеют записывать BMP с архивацией RLE (однако все стандартные средства, в т.ч. средства системы Windows, читают такой сжатый файл нормально). Всегда полезно помнить, что на размер файла оказывают существенное влияние большое количество параметров (вариант реализации алгоритма, параметры алгоритма (как внутренние, так и задаваемые пользователем), порядок цветов в палитре и многое другое). Например, для абсолютно черного изображения 1000х1000х256 градаций серого в формате JPEG с помощью одной программы при различных параметрах всегда получался файл примерно в 7 килобайт. В то же время, меняя опции в другой программе, я получил файлы размером от 4 до 68 Кб (всего-то на порядок разницы). При этом декомпрессированное изображение для всех файлов было одинаковым — абсолютно черный квадрат (яркость 0 для всех точек изображения). Дело в том, что даже для простых форматов одно и то же изображение в одном и том же формате с использованием одного и того же алгоритма архивации можно записать в файл несколькими корректными способами. Для сложных форматов и алгоритмов архивации возникают ситуации, когда многие программы сохраняют изображения разными способами. Такая ситуация, например, сложилась с форматом TIFF (в силу его большой гибкости). Долгое время по-разному сохраняли изображения в формат JPEG, поскольку соответствующая группа ISO (Международной Организации по Стандартизации) подготовила только стандарт алгоритма, но не стандарт формата. Сделано так было для того, чтобы не вызывать “войны форматов”. Абсолютно противоположное положение сейчас с фрактальной компрессией, поскольку есть стандарт “де-факто” на сохранение фрактальных коэффициентов в файл (стандарт формата), но алгоритм их нахождения (быстрого нахождения!) является технологической тайной создателей программ-компрессоров. В результате для вполне стандартной программы-декомпрессора могут быть подготовлены файлы с коэффициентами, существенно различающиеся как по размеру, так и по качеству получающегося изображения. Приведенные примеры показывают, что встречаются ситуации, когда алгоритмы записи изображения в файл в различных программах различаются. Однако гораздо чаще причиной разницы файлов являются разные параметры алгоритма. Как уже говорилось, многие алгоритмы позволяют в известных пределах менять свои параметры, но не все программы позволяют это делать пользователю. Вывод 2: Если вы не умеете пользоваться программами архивации или пользуетесь программами, в которых “для простоты использования” убрано управление параметрами алгоритма — не удивляйтесь, почему для отличного алгоритма компрессии в результате получаются большие файлы. |
Рекурсивный (волновой) алгоритмАнглийское название рекурсивного сжатия — wavelet. На русский язык оно переводится как волновое сжатие, и как сжатие с использованием всплесков. Этот вид архивации известен довольно давно и напрямую исходит из идеи использования когерентности областей. Ориентирован алгоритм на цветные и черно-белые изображения с плавными переходами. Идеален для картинок типа рентгеновских снимков. Коэффициент сжатия задается и варьируется в пределах 5-100. При попытке задать больший коэффициент на резких границах, особенно проходящих по диагонали, проявляется “лестничный эффект” — ступеньки разной яркости размером в несколько пикселов. Идея алгоритма заключается в том, что мы сохраняем в файл разницу — число между средними значениями соседних блоков в изображении, которая обычно принимает значения, близкие к 0. Так два числа a2i и a2i+1 всегда можно представить в виде b1i=(a2i+a2i+1)/2 и b2i=(a2i-a2i+1)/2. Аналогично последовательность ai может быть попарно переведена в последовательность b1,2i. Разберем конкретный пример: пусть мы сжимаем строку из 8 значений яркости пикселов (ai): (220, 211, 212, 218, 217, 214, 210, 202). Мы получим следующие последовательности b1i, и b2i: (215.5, 215, 215.5, 206) и (4.5, -3, 1.5, 4). Заметим, что значения b2i достаточно близки к 0. Повторим операцию, рассматривая b1i как ai. Данное действие выполняется как бы рекурсивно, откуда и название алгоритма. Мы получим из (215.5, 215, 215.5, 206): (215.25, 210.75) (0.25, 4.75). Полученные коэффициенты, округлив до целых и сжав, например, с помощью алгоритма Хаффмана с фиксированными таблицами, мы можем поместить в файл. Заметим, что мы применяли наше преобразование к цепочке только два раза. Реально мы можем позволить себе применение wavelet- преобразования 4-6 раз. Более того, дополнительное сжатие можно получить, используя таблицы алгоритма Хаффмана с неравномерным шагом (т.е. нам придется сохранять код Хаффмана для ближайшего в таблице значения). Эти приемы позволяют достичь заметных коэффициентов сжатия. Упражнение: Мы восстановили из файла цепочку (215, 211) (0, 5) (5, -3, 2, 4) (см. пример). Постройте строку из восьми значений яркости пикселов, которую воссоздаст алгоритм волнового сжатия. Алгоритм для двумерных данных реализуется аналогично. Если у нас есть квадрат из 4 точек с яркостями a2i,2j, a2i+1, 2j, a2i, 2j+1, и a2i+1, 2j+1, то 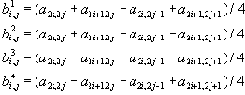
В течение последних 10 летВ течение последних 10 лет в рамках компьютерной графики бурно развивается совершенно новая область — алгоритмы архивации изображений. Появление этой области обусловлено тем, что изображения — это своеобразный тип данных, характеризуемый тремя особенностями: Изображения (как и видео) занимают намного больше места в памяти, чем текст. Так, скромная, не очень качественная иллюстрация на обложке книги размером 500x800 точек, занимает 1.2 Мб — столько же, сколько художественная книга из 400 страниц (60 знаков в строке, 42 строки на странице). В качестве примера можно рассмотреть также, сколько тысяч страниц текста мы сможем поместить на CD-ROM, и как мало там поместится качественных несжатых фотографий. Эта особенность изображений определяет актуальность алгоритмов архивации графики. Второй особенностью изображений является то, что человеческое зрение при анализе изображения оперирует контурами, общим переходом цветов и сравнительно нечувствительно к малым изменениям в изображении. Таким образом, мы можем создать эффективные алгоритмы архивации изображений, в которых декомпрессированное изображение не будет совпадать с оригиналом, однако человек этого не заметит. Данная особенность человеческого зрения позволила создать специальные алгоритмы сжатия, ориентированные только на изображения. Эти алгоритмы обладают очень высокими характеристиками. Мы можем легко заметить, что изображение, в отличие, например, от текста, обладает избыточностью в 2-х измерениях. Т.е. как правило, соседние точки, как по горизонтали, так и по вертикали, в изображении близки по цвету. Кроме того, мы можем использовать подобие между цветовыми плоскостями R, G и B в наших алгоритмах, что дает возможность создать еще более эффективные алгоритмы. Таким образом, при создании алгоритма компрессии графики мы используем особенности структуры изображения. Всего на данный момент известно минимум три семейства алгоритмов, которые разработаны исключительно для сжатия изображений, и применяемые в них методы практически невозможно применить к архивации еще каких-либо видов данных. Для того, чтобы говорить об алгоритмах сжатия изображений, мы должны определиться с несколькими важными вопросами: Какие критерии мы можем предложить для сравнения различных алгоритмов? Какие классы изображений существуют? Какие классы приложений, использующие алгоритмы компрессии графики, существуют, и какие требования они предъявляют к алгоритмам? Рассмотрим эти вопросы подробнее. Попробуем на этом этапе сделатьПопробуем на этом этапе сделать некоторые обобщения. С одной стороны, приведенные выше алгоритмы достаточно универсальны и покрывают все типы изображений, с другой — у них, по сегодняшним меркам, слишком маленький коэффициент архивации. Используя один из алгоритмов сжатия без потерь, можно обеспечить архивацию изображения примерно в два раза. В то же время алгоритмы сжатия с потерями оперируют с коэффициентами 10-200 раз. Помимо возможности модификации изображения, одна из основных причин подобной разницы заключается в том, что традиционные алгоритмы ориентированы на работу с цепочкой. Они не учитывают, так называемую, “когерентность областей” в изображениях. Идея когерентности областей заключается в малом изменении цвета и структуры на небольшом участке изображения. Все алгоритмы, о которых речь пойдет ниже, были созданы позднее специально для сжатия графики и используют эту идею. Справедливости ради следует отметить, что и в классических алгоритмах можно использовать идею когерентности. Существуют алгоритмы обхода изображения по “фрактальной” кривой, при работе которых оно также вытягивается в цепочку; но за счет того, что кривая обегает области изображения по сложной траектории, участки близких цветов в получающейся цепочке удлиняются. |