Аксиомы вывода Классификация покрытий
При декомпозиции исходные отношения опираются не на все Ф/З, а только на те, которые являются подмножеством так называемого минимального покрытия. Чтобы осуществить переход от множества Ф/З к минимальному покрытию необходимо установить так называемые избыточные Ф/З. Пусть дано множество Ф/З F на схеме R. При этом X и Y принадлежат данной схеме. Ф/З X®Y, является избыточной, если она следует из множества: F – (X®Y).
Для вывода Ф/З используются правила вывода или аксиомы вывода: Армстронга и ß-аксиомы.
Аксиомы Армстронга:
Рефлексивность: X®X (F1);
Пополнение: если X®Y, то XZ®Y (F2); Пополнение возможно только для левой части, при этом полученную левую часть нельзя разложить обратно!
Аддитивность: если X®Y, X®Z, то X®YZ (F3);
Проективность: если X®YZ, то X®Y, X®Z (F4);
Транзитивность: если X®Y, Y®Z, то X®Z (F5);
Псевдотранзитивность: если X®Y, YZ®W, то XZ®W (F6).
Из всех представленных шести аксиом, три являются независимыми (F1, F2, F6), а остальные можно вывести на основании этих. При выводе одних Ф/З на основании других, выстраиваются цепочки Ф/З полученных на основании аксиом вывода. Их называются выводы.
ß-аксиомы:
Рефлексивность: X®X (ß1);
Накопление: если X®YZ, Z®CW, то X®YZCW (ß2);
Доказательство:
а. X®YZ (дано)
б. X®Z (F4) {а}
в. Z®CW (дано)
г. Z®C (F4) {в}
д. Z®W (F4) {в}
е. X®C (F5) {б, г}
ж. X®W (F5) {б, д}
з. X®YZCW (F3) {а, е, ж}
Проективность: если X®YZ, то X®Z (ß3).
Классификация покрытий:
Покрытие – это эквивалентные множества Ф/З. При этом, под эквивалентным множеством понимают такие множества F1 и F2 на схеме R, когда они взаимообратные, т.е., из множества F1 путем применения аксиом вывода, может быть получено F2, а из множества F2, аналогичным способом, может быть получено обратное множество F1.
Различают следующие покрытия:
Неизбыточное – покрытие, которое не содержит избыточных Ф/З. У каждого множества Ф/З может быть несколько не избыточных покрытий.
Вид не избыточного покрытия во многом определяется порядком, в котором Ф/З проверяются на избыточность. F={A®B, A®C, A®BC}.Получаем не избыточные покрытия: F1={A®B, A®C} или F2={A®BC}.
Алгоритм получения:
ü
выбирается Ф/З из исходного множества Ф/З (любая) и проверяется ее возможность получения их оставшихся элементов множества Ф/З с помощью аксиом вывода;
ü если выбранная Ф/З не следует из оставшихся элементов множества Ф/З, то она оставляется в исходном множестве;
ü если вывод Ф/З возможен, то она удаляется. Вывод продолжается до тех пор, пока не будет проверена каждая Ф/З.
Минимальное – это не избыточное покрытие, содержащее наименьшее количество функциональных зависимостей. Их так же может быть несколько. Если рассматривать Ф/З F1 и F2, то они оба не избыточные, но минимальным среди них является только F2.
Редуцированное – это множество, содержащее в себе только редуцированные Ф/З. Ф/З называется редуцированной, если она слева и справа не содержит посторонних атрибутов. Например, F3={A®B, AB®C}. Ф/З AB®C, содержит лишний атрибут в левой части – B. Доказать, что A®C.
а. A®A (ß1)
б. A®B (дано)
в. A®AB (ß2 из а и б)
г. AB®C (дано)
д. A®ABC (ß2 из в и г)
е. A®C (ß3 из д)
Таким образом, покрытие F4={A®B, A®C} – является редуцированным, но не минимальным.
Алгоритм получения:
ü удаляются посторонние атрибуты из левой части Ф/З;
ü удаляются все посторонние атрибуты из правой части Ф/З;
ü удаляются все Ф/З вида: «A®0»
Каноническое – неизбыточное покрытие, состоящее из полных Ф/З, правая часть которых содержит только один атрибут.
Канонические покрытия выполняют вспомогательную роль, при получении минимального и неизбыточного покрытий. Декомпозицию на таком покрытии не производят.
Алгоритм получения:
ü применяют аксиомы проективности; все Ф/З приводят к виду «X®A»;
ü из полученного множества удаляются все избыточные Ф/З;
ü в оставшихся Ф/З, удаляются все избыточные атрибуты.
Таким образом, вновь полученное множество Ф/З, становится редуцированным.
Пример: F5 = { A®BE, AB®CD, C®DE, B®E}
|
A®E – избыточная Ф/З A®B AB®C – не редуцир. (лишний атр. B) AB®D – не редуцир. (лишний атр. B) C®E C®D B®E |
1.A®B 2.A®C 3.A®D – избыточн. (F5 из 2 и 4) 4.C®D 5.C®E 6.B®E |
Оптимальное – это такое покрытие, для которого не существует эквивалентного ему множества с еще меньшим числом вхождений атрибутных символов.
F7={ABC®DB, AB®EC, E®AB} Оптимальное: F8={AB®E, EC®D, E®AB}
Кольцевое – используется в качестве основания для декомпозиции на минимальном покрытии Ф/З с эквивалентными левыми частями.
Множество Ф/З называется кольцевым покрытием множества F, если оно эквивалентно ему и представлено виде комплексных Ф/З.
Например, для множества F9 = {A®B, B®A, B®C, C®D} кольцевое покрытие будет иметь вид: G1 = {(A; B) ®C; (C) ®D}.
Кольцевые покрытия могут быть: не избыточными, минимальными, редуцированными, оптимальными.
Архитектура многопользовательских СУБД
(Коннолли, с.95-99)
Типовые архитектурные решения, используемые при реализации многопользовательских СУБД – телеобработка, файловый сервер и технология «клиент-сервер».
1. Телеобработка

Один компьютер с единственным процессором соединен с терминалами, как показано на рисунке. Терминалы – неинтеллектуальные устройства, не способные функционировать самостоятельно. С центральным процессором терминалы связываются с помощью кабелей, по которым посылаются сообщения пользовательским приложениям. В свою очередь пользовательские приложения обращаются к необходимым службам СУБД. При такой архитектуре основная нагрузка возлагается на центральный компьютер, который должен выполнять не только действия прикладных программ и СУБД, но значительную работу по обслуживанию терминалов (форматирование данных, выводимых на экран терминалов).
2. Файловый сервер
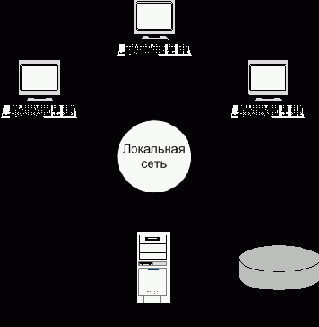
В среде файлового сервера обработка данных распределена в сети (ЛВС). Файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД. Пользовательские приложения и СУБД размещены и функционируют на отдельных рабочих станциях, и обращаются к файловому серверу по мере необходимости получения доступа к нужным файлам. Таким образом, файловый сервер функционирует просто как совместно используемый жесткий диск. СУБД на каждой рабочей станции посылает запросы файловому серверу по всем необходимым ей данным, которые хранятся на диске файл-сервера. Такой подход характеризуется значительным сетевым трафиком, что может привести к снижению производительности всей системы.
Недостатки файл-серверной архитектуры: большой объем сетевого трафика; на каждой рабочей станции должна находиться полная копия СУБД; управление параллельностью, восстановлением и целостностью усложняется, т.к. доступ к одним и тем же файлам могут осуществлять сразу несколько экземпляров СУБД.
3. Технология «клиент-сервер»
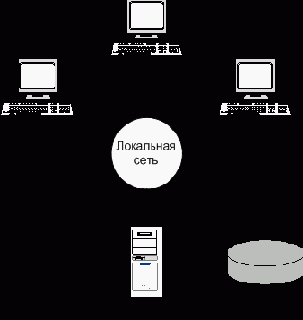
«Клиент/сервер» означает такой способ взаимодействия программных компонентов, при котором они образуют единую систему. Существует некий клиентский процесс, требующий определенных ресурсов, а также серверный процесс, который эти ресурсы предоставляет.
В контексте БД клиент управляет пользовательским интерфейсом и логикой приложения, действуя как сложная рабочая станция, на которой выполняются приложения БД. Клиент принимает от пользователя запрос, проверяет синтаксис и генерирует запрос к БД. Затем он передает сообщение серверу, ожидает поступления ответа и форматирует полученные данные для представления их пользователю. Сервер принимает и обрабатывает запросы к БД, а затем передает полученные результаты обратно клиенту.
Преимущества от использования данной технологии: 1) более широкий доступ к существующим БД; 2) повышение общей производительности системы (из-за нахождения клиентов и сервера на разных компьютерах их процессоры способны выполнять приложения параллельно); 3) снижение стоимости аппаратного обеспечения (мощный компьютер необходим только серверу для хранения и управления БД); 4) сокращение коммуникационных расходов (приложения выполняют часть операций на клиентских машинах и посылают через сеть только запросы к БД); 5) повышение уровня непротиворечивости данных (сервер может самостоятельно управлять проверкой целостности данных, каждому приложению не придется выполнять собственную проверку); 6) данная архитектура естественно отображается на архитектуру открытых систем.
Двухуровневая архитектура «клиент/сервер» может быть расширена до трехуровневой, при которой функциональная часть прежнего, толстого (интеллектуального) клиента разделяется на две части. В трехуровневой архитектуре тонкий (неинтеллектуальный) клиент на рабочей станции управляет только пользовательским интерфейсом, тогда как средний уровень обработки данных управляет всей остальной логикой приложения. Третий уровень – сервер БД.
Целостность базы данных
Основное из требований предъявляемых к БД – надежность хранения информации, что в свою очередь невозможно без согласованности данных. Целостность базы – взаимная согласованность отдельных фрагментов данных и их корректность. Полагая также, что согласованность имеет место, когда все порции данных в БД единообразно смоделированы и включены в систему, а данные корректны, если они достоверны, точны и значимы, сформулируем ниже ряд правил, которые позволяют поддерживать согласованность и корректность данных в БД.
Существуют два основных правила поддержания целостности БД:
1) Целостности объектов. В частности оно задает ограничение на значения атрибутов, которые должны принадлежать определенному домену и накладывает запрет на неопределенные значения атрибутов первичного ключа отношения. Первичный ключ – минимальный идентификатор, который используется для уникальной идентификации картежа. Это значит, что никакое подмножество первичного ключа не может быть достаточным для уникальной идентификации картежей. Если допустить присутствие определителя NULL в любой части первичного ключа, это равноценно утверждению, что не все его атрибуты необходимы для уникальной идентификации картежей, что противоречит определению первичного ключа.
2) Ссылочная целостность. Значения внешних ключей отношения должны быть адекватны значениям соответствующих первичных ключей. С целью обеспечения этой согласованности накладывается целый ряд ограничений на выполнение основных операций (удаление, добавление, редактирование) над кортежами отношений.
Так, например, для избежания несогласованности при выполнении операции удаления следует выполнить одну из следующих операций:
·
Запретить удаление записи в ссылочном отношении, если в ссылающемся отношении есть кортеж, в котором значение внешнего ключа совпадает со значением первичного ключа в ссылочном отношении.
· Выполнить каскадное удаление. При удалении записи в ссылочном отношении, удалить все соответствующие записи в ссылающемся отношении.
При выполнении операции редактирования
следует:
· Запретить обновление первичного ключа записи в ссылочном отношении, если в ссылающемся отношении есть кортеж, в котором значение внешнего ключа совпадает со значением первичного ключа в ссылочном отношении.
· Выполнить каскадное редактирование. При редактировании записи в ссылочном отношении, отредактир-ть все соответствующие записи в ссылающемся отношении.
При выполнении операции добавления
следует: запретить добавление записи в ссылающееся отношение, если в ссылочном отношении нет кортежа, в к-ом значение первичного ключа совпадает со значением внешн. ключа в ссылающемся отношении.
Кроме 2-х основных правил существует корпоративное ограничение целостности - дополнительные правила поддержки целостности данных, определяемые пользователями или администратором БД. Например, если в одном отделении не может работать больше 20 сотрудников, то пользователь может указать это правило, а СУБД следить за его выполнением.
ЕR – модель Генерация отношений
Диаграммы "сущность-связь" (Entity-Relationship) предназначены для разработки моделей данных и обеспечивают стандартный способ определения данных и отношений между ними. Фактически с помощью ERD осуществляется детализация хранилищ данных проектируемой системы, а также документируются сущности системы и способы их взаимодействия, включая идентификацию объектов, важных для предметной области (сущностей), свойств этих объектов (атрибутов) и их отношений с другими объектами (связей).
Первый вариант модели сущность-связь был предложен в 1976 г. Питером Пин-Шэн Ченом. В дальнейшем многими авторами были разработаны свои варианты подобных моделей (нотация Мартина, нотация IDEF1X, нотация Баркера и др.). По сути, все варианты диаграмм сущность-связь исходят из одной идеи - рисунок всегда нагляднее текстового описания. Все такие диаграммы используют графическое изображение сущностей предметной области, их свойств (атрибутов), и взаимосвязей между сущностями.
ER-диаграммамы с позиции нотации Чена.
Основные понятия ER-диаграмм:
Сущность - это класс однотипных объектов, информация о которых должна быть учтена в модели. Каждая сущность должна иметь наименование, выраженное существительным в единственном числе. Каждая сущность в модели изображается в виде прямоугольника с наименованием.
Экземпляр сущности - это конкретный представитель данной сущности. Например, представителем сущности "Игрок" может быть "Игрок Иванов". Экземпляры сущностей должны быть различимы, т.е. сущности должны иметь некоторые свойства, уникальные для каждого экземпляра этой сущности.
Атрибут сущности - это именованная характеристика, являющаяся некоторым свойством сущности. Наименование атрибута должно быть выражено существительным в единственном числе (возможно, с характеризующими прилагательными).
Ключ сущности - это неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности. Неизбыточность заключается в том, что удалением любого атрибута из ключа нарушается его уникальность.
Сущность может иметь несколько различных ключей. Ключевые атрибуты изображаются на диаграмме подчеркиванием.
Связь - это некоторая ассоциация между двумя сущностями. Одна сущность может быть связана с другой сущностью или сама с собою. Связи позволяют по одной сущности находить другие сущности, связанные с нею. Графически связь изображается линией, соединяющей две сущности. Каждая связь имеет два конца и одно или два наименования. Наименование обычно выражается в неопределенной глагольной форме: "иметь", "принадлежать" и т.п. Каждое из наименований относится к своему концу связи. Иногда наименования не пишутся ввиду их очевидности.
Каждая связь может иметь один из следующих типов связи:
Связь типа один-к-одному
означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две.
Связь типа один-ко-многим
означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны "один") называется родительской, правая (со стороны "много") - дочерней.
Связь типа много-ко-многим
означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности.
Каждая связь может иметь одну из двух модальностей связи:
·
Модальность "может" означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром.
· Модальность "должен" означает, что экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности.
Связь может иметь разную модальность с разных концов.
Объекты рассматриваемой нотации отображаются следующим образом:
|
Название объекта |
Отображение |
|
Сущность |
 |
|
Сущность с обязательным классом принадлежности |
 |
|
Сущность с необязательным классом принадлежности |
 |
|
Связь |
 |
|
Связь со свободным атрибутом (или атрибутом связи) |
 |
|
Степень связи |
1:1 (“один к одному”) 1:n (n:1) (“один ко многим”) n:m (“многие ко многим”) |
|
Свободный атрибут |
отображается в овале |
|
Связь вида супертип/подтип |
 |

R(препод-дисципина) = {Таб. №,
ФИО, название дисциплины}
Правило 2: При степени связи 1:1 и необязательном классе принадлежности одной из сущностей формируется 2 отношения по одному на каждую сущность, при этом в отношении соответствующее сущности с обязательным классом принадлежности в качестве обязательного атрибута входит ключ сущности с необязательным классом принадлежности. Ключом вновь сформированного отношения может быть ключ любой из сущности.

R(препод) = {таб №, ФИО, разряд, название дисциплины}
R(дисциплина) = {название дисциплины, вид контроля}
Правило 3: при степени связи 1:1 и необязательном классе принадлежности обеих сущностей формируется три отношения по одному на каждую сущность + отношение связи. В отношение связи в качестве обязательных атрибутов входят ключи обеих сущностей. Ключом связи может быть любой из ключей.
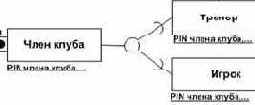
Правило 4: при степени связи 1:n и обязательном классе принадлежности n-связной сущности формируется 2 отношения, при этом в отношение соответствующее n-связной сущности в качестве обязательного атрибута войдет ключ односвязной сущности.
Ключом этого отношения будет ключ n-связной сущности.

R(препод) = {таб №, ФИО, разряд, название дисциплины}
R(дисциплина) = {название дисциплины, вид контроля}
Обоснуем данное правило:
Правило 5: при степени связи 1:n и необязательном классе принадлежности n-связной сущности формируется 3 отношения по одному на каждую сущность + отношение связи, куда в качестве обязательного атрибута входят ключи обеих сущностей, ключом отношения будет ключ n-связной сущности.
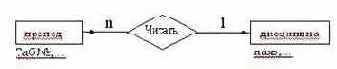
R(препод) ={таб №, фио, разряд}
R(дисципина) = {название дисциплины, вид отчетности}
R(читать) = {таб №, название дисциплины}
Обоснуем данное правило:
Следуя правилу у нас получилось 2 отношения с одинаковым ключом, но в данном случае объединение данных отношений будет не верно, так как модальность связи в данном отношении “может”, а следовательно при объединении отношений получиться что какому то атрибуту отношения может не соответствовать значение, а следовательно будут присутствовать NULL поля. Чтобы избежать NULL полей и вводится 3 связь, которая позволяет избежать неопределенности.
Правило 6: при степени связи m:n независимо от класса принадлежности обеих сущностей формируется 3 отношения по одному на каждую сущность + отношение связи, куда в качестве обязательных атрибутов входят ключи обеих сущностей, ключом данного отношения будут ключи обеих сущностей.

R(препод) = {таб №, фио, разряд}
R(дисциплина) = {название дисциплины, вид отчетности}
R(читать) = {таб №, название дисциплины}
Формализация реляционной базы данных
Реляционная база данных (БД) – это совокупность отношений. Отношением
называется таблица, которая обладает следующими свойствами:
· все элементы каждого ее столбца имеют одинаковую природу;
· каждый столбец имеет уникальное имя;
· в таблице нет двух одинаковых строк;
· информативность таблицы не зависит от порядка расположения строк или столбцов.
Строки отношения называются кортежами. Каждый столбец отношения имеет уникальное имя, которое называется наименованием атрибута или просто атрибутом. Множество допустимых значений атрибута образует домен атрибута, который обозначается как dom (н-р, домен атрибута А – dom(A)), а множество допустимых значений всех атрибутов отношения - домен отношения
(обозначается буквой D). Количество атрибутов в отношении, как правило, остается неизменным в течение жизни БД и называется степенью отношения. Количество кортежей определяет мощность отношения (кардинальное число), которая в свою очередь постоянно изменяется во времени.
Реляционные базы данных составляют основу оперативных хранилищ информации, где над данными осуществляется 3 операции: добавление, правка, удаление. Декомпозиция обусловлена проблемами, которые возникают при выполнении этих операций.
У реляционной модели БД существует аппарат, который позволяет формализовать операции этой модели (реляционная алгебра). Также доступ к данным должен быть независим от ПО.
Формализация реляционной БД – это представление БД в виде отношения со всеми вытекающими из этого последствиями. Также реляционная модель требует, чтобы типы используемых данных были простыми.
Функции администратора базы данных Функции администратора данных
Обычно управление данными и базой данных предусматривает управление и контроль за СУБД и помещёнными в неё данными. При централизованном управлении на предприятии, использующем базу данных, есть человек, который несет основную ответственность за данные предприятия. Это администратор данных.
Администратор данных (АД) отвечает за управление данными, включая планирование базы данных, разработку и сопровождение стандартов, бизнес - правил и деловых процедур, а также за концептуальное и логическое проектирование базы данных. АД консультирует и дает свои рекомендации, руководству высшего звена, контролируя соответствие общего направления развития базы данных установленным корпоративным целям. В обязанности администратора данных входит принятие решений о том, какие данные необходимо вносить в базу данных в первую очередь, а также выработка требований по сопровождению и обработке данных после их занесения в базу данных.
Администратор базы данных
(АБД) – человек, обеспечивающий техническую поддержку с целью реализации принятых администратором данных решений. Он отвечает за физическую реализацию базы данных, включая физическое проектирование и воплощение проекта, за обеспечение безопасности и целостности данных, за сопровождение операционной системы, а также за обеспечение максимальной производительности приложений и пользователей.
АД и АБД отвечаю за действиями, связанными с корпоративными данными и корпоративной БД соответственно.
В таблице 1 представлены этапы ЖЦ БД с указание роли АБ и АБД:
| Этап | Основная роль | Вспом-я роль | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Планирование разработки БД | АД | АБД | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Определение требований к системе | АД | АБД | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Сбор и анализ требований пользователей |
Функции и архитектура распределённых СУБДРаспределенная СУБД (СУРБД) – программный комплекс, предназначенный для управления распределенными базами данных и позволяющий сделать распределенность информации прозрачной для конечного пользователя. Типичная СУРБД должна обеспечивать, по крайней мере тот же набор функциональных возможностей, что и централизованная СУБД. Функции СУБД: · Обеспечивает хранение информации. · Должна позволять организовывать структуры данных. · Обеспечивать эффективный доступ к данным и модернизировать их. · Удаление, добавление, редактирование. · Обеспечивает санкционированный доступ к данным. · Позволяет создавать пользовательский интерфейс. · Позволяет осуществлять управление транзакциями, при этом обеспечивает поддержание основных свойств транзакций: Кроме того, СУРБД должна предоставлять следующий набор функциональных возможностей: · Расширенные службы установки соединений должны обеспечивать доступ к удаленным сайтам позволять передавать запросы и данные между сайтами, входящими в сеть. · Расширенные средства ведения каталога, позволяющие сохранять сведения о распределенности данных в сети. · Средства обработки распределенных запросов, включая механизмы оптимизации запросов и организации удаленного доступа. · Расширенные функции управления параллельностью, позволяющие поддерживать целостность реплицируемых данных. · Расширенные функции восстановления, учитывающие возможность отказов работ отдельных сайтов и отказов линий связи. Архитектура СУРБД Трехуровневая архитектура ANSI-SPARС для СУБД представляет собой типовое решение для централизованных СУБД. Однако распределенные СУБД имеют множество отличий, которые весьма сложно отразить в некотором эквивалентном архитектурном решении, приемлемом для большинства случаев. Однако было бы полезно найти некоторое рекомендуемое решение, учитывающее особенности работы с распределёнными данными. Один из примеров рекомендуемой архитектуры включает следующие элементы: · набор глобальных внешних схем · глобальную концептуальную схему · схему фрагментации и схему распределения · набор схем для каждой локальной СУБД, отвечающих требованиям трёхуровневой архитектуры ANSI-SPARС. Соединительные линии на схеме представляют преобразование выполняемые при переходе между схемами различных типов, в зависимости от поддерживаемого уровня прозрачности некоторые из уровней рекомендуемой архитектуры могут быть опущены Глобальная концептуальная схема. Глобальная концептуальная схема представляет собой логическое описание всей базы данных, представляющее её так, как будто она не является распределённой. Этот уровень СУРБД соответствует концептуальному уровню архитектуры ANSI-SPARС и содержит определения сущностей, связей, требования защиты и ограничений поддержки целостности информации. Он обеспечивает физическую независимость данных от распределённой среды. Логическую независимость данных обеспечивают глобальные внешние схемы. Схемы фрагментации и распределения. Схемы фрагментации содержат описание того, как данные должны логически распределяться по разделам, схема распределения является описанием того, где расположены имеющиеся данные. Схема распределения учитывает все организованные в системе процессы репликации. Локальные схемы. Каждая локальная СУБД имеет свой собственный набор схем. Локальная концептуальная и локальная внутренняя схемы полностью соответствуют эквивалентным уровням архитектуры ANSI-SPARС. Локальная схема отображения используется для отражения фрагментов в схеме распределения во внутренние объекты локальной базы данных. Эти элементы являются зависимыми от типа используемой СУБД и служат основой для построения гетерогенных СУРБД. Функции и компоненты СУБД(Коннолли, с. 88-95) СУБД – это программное обеспечение, с помощью которого пользователи могут определять, создавать и поддерживать БД, а также осуществлять к ней контролируемый доступ. Функции СУБД (первые восемь предложены Коддом – сервисы, которые должны быть реализованы в любой полномасштабной СУБД; остальные две – добавлены Коннолли): 1. Хранение, извлечение и обновление данных СУБД должна предоставлять пользователям возможность сохранять, извлекать и обновлять данные в БД. Способ реализации этой функции в СУБД должен позволять скрывать от конечного пользователя внутренние детали физической реализации системы (например, файловую организацию или используемые структуры хранения). 2. Каталог, доступный конечным пользователям СУБД должна иметь доступный конечным пользователям каталог, в котором хранится описание элементов данных. Системный каталог, или словарь данных, является хранилищем информации, описывающей данные в базе данных (по сути, это данные о данных, т.е. метаданные). Обычно в системном каталоге хранятся следующие сведения: 1) имена, типы и размеры элементов данных; 2) имена связей; 3) накладываемые на данные ограничения поддержки целостности; 4) имена санкционированных пользователей, которым предоставлено право доступа к данным; 5) внешняя, концептуальная и внутренняя схемы и отображения между ними; 6) статистические данные, например частота транзакций и счетчики обращений к объектам БД. Системный каталог позволяет достичь определенных преимуществ: 1) информация о данных может быть централизованно собрана и сохранена, что позволит контролировать доступ к этим данным, как и к любому другому ресурсу; 2) можно определить смысл данных, что поможет другим пользователям понять их предназначение; 3) упрощается сообщение, т.к. сохраняются точные определения смысла данных; 4) благодаря централизованному хранению избыточность и противоречивость описания отдельных элементов могут быть легко обнаружены; 5) внесенные в БД изменения могут быть запротоколированы; 6) последствия любых изменений могут быть определены еще до их внесения; 7) меры обеспечения безопасности могут быть дополнительно усилены; 8) появляются новые возможности организации поддержки целостности данных; 9) может выполняться аудит сохраняемой информации. 3. Поддержка транзакций СУБД должна иметь механизм, который гарантирует выполнение либо всех операций обновления данной транзакции, либо ни одной из них, то есть при сбое транзакции БД должна быть возвращена в непротиворечивое состояние. 4. Сервисы управления параллельностью СУБД должна иметь механизм, который гарантирует корректное обновление БД при параллельном выполнении операций обновления многими пользователями. 5. Сервисы восстановления СУБД должна предоставлять средства восстановления БД на случай какого-либо ее повреждения или разрушения. 6. Сервисы контроля доступа к данным СУБД должна иметь механизм, гарантирующий возможность доступа к БД только санкционированных пользователей. 7. Поддержка обмена данными СУБД должна обладать способностью к интеграции с коммуникационным программным обеспечением. То есть, необходимо чтобы была возможность установить одну централизованную БД и использовать ее как общий ресурс для всех существующих пользователей, то есть обеспечить распределенную обработку. 8. Службы поддержки целостности данных СУБД должна обладать инструментами контроля за тем, чтобы данные и их изменения соответствовали заданным правилам. Целостность БД означает корректность и непротиворечивость хранимых данных. Она выражается обычно в виде ограничений или правил сохранения непротиворечивости данных, которые не должны нарушаться в базе. 9. Службы поддержки независимости от данных СУБД должна обладать инструментами поддержки независимости программ от фактической структуры БД. Независимость от данных обычно достигается за счет реализации механизма поддержки представлений или подсхем. 10. Вспомогательные службы Вспомогательные утилиты обычно предназначены для оказания помощи администратору БД в эффективном администрировании БД. Примеры подобных утилит: 1) утилиты импортирования, предназначенные для загрузки БД из плоских файлов и утилиты экспортирования для выгрузки БД в плоские файлы; 2) средства мониторинга, предназначенные для отслеживания характеристик функционирования и использования БД; 3) программы статистического анализа, позволяющие оценить производительность или степень использования БД; 4) инструменты реорганизации индексов, предназначенные для перестройки индексов и обработки случаев их переполнения; 5) инструменты сборки мусора и перераспределения памяти для физического устранения удаленных записей с запоминающих устройств, объединения освобожденного пространства и перераспределения памяти в случае необходимости. Компоненты СУБД Основные программные компоненты среды СУБД представлены на рисунке. 1. Процессор запросов Основной компонент СУБД, который преобразует запросы в последовательность низкоуровневых инструкций для контроллера БД  2. Контроллер БД Взаимодействует с запущенными пользователем прикладными программами и запросами. Принимает запросы и проверяет внешние и концептуальные схемы для определения тех концептуальных записей, которые необходимы для удовлетворения требований запроса. Затем вызывает контроллер файлов для выполнения поступившего запроса. 3. Контроллер файлов Манипулирует предназначенными для хранения данных файлами и отвечает за распределение доступного дискового пространства. Создает и поддерживает список структур и индексов, определенных во внутренней схеме. Не управляет физическим вводом и выводом данных непосредственно, а передает запросы соответствующим методам доступа. 4. Препроцессор языка DML Преобразует внедренные в прикладные программы DML-операторы в вызовы стандартных функций базового языка. Для генерации соответствующего кода должен взаимодействовать с процессором запросов. 5. Компилятор языка DDL Преобразует DDL-команды в набор таблиц, содержащих метаданные. Затем эти таблицы сохраняются в системном каталоге, а управляющая информация – в заголовках файлов с данными. 6. Контроллер словаря Управляет доступом к системному каталогу и обеспечивает работу с ним. Системный каталог доступен большинству компонентов СУБД. КлючиКлюч – идентификатор, по которому однозначно определяется картеж (строка) в отношении. Ключ – идентификатор, не содержащий внутри себя другого идентификатора. Одно отношение может иметь несколько ключей. В качестве активного ключа выбирается только один, его называют первичным (активным, выделенным ключом; на схеме первичный ключ выделяется подчеркиванием), остальные ключи называют возможными. Требования при выборе первичного ключа: ü Минимальный по длине (оптимальный вариант, когда ключ из одного атрибута); ü Ключ не должен редактироваться в процессе жизни БД. Например, нельзя в качестве первичного ключа использовать № паспорта или какого-либо документа, значение которого может меняться в течение жизни системы. Если в отношении нет ключа, отвечающего всем выше перечисленным требованиям, то вводится так называемый суррогатный ключ - атрибут, значение которого для каждого кортежа уникально и является внутренним делом системы. Введение суррогатного ключа целесообразно проводить на завершающем этапе. Суррогатный ключ позволяет уменьшить объем хранящихся в информационной системе данных. Кроме того, суррогатный ключ обеспечивает выполнение условия целостности на уровне отношения, которое заключается в том, что каждый атрибут первичного ключа должен иметь определенное значение. Атрибут, входящий в ключ отношения (первичный или возможный), называется основным атрибутом. Идентификатор, содержащий избыточные атрибуты называется суперключом, суперключ не ключ. Еще раз сформулируем дополнительные требования к ключам: · Ключи не должны содержать NULL признаков атрибутов. · Значение ключа не должно корректироваться в процессе жизни данных, или вероятность их корректировки должна быть очень мала. · Если отношение имеет несколько ключей, то предпочтение при выборе первичного ключа следует отдать ключу с меньшим количеством атрибутов. · Допускается введение так называемого суррогатного ключа, значение которого есть внутреннее дело системы и, как правило, не несет никакой смысловой нагрузки. Достоинством суррогатного ключа является то, что он не требует редактирования и, как правило, краток, в большинстве случаев содержит не более 10 символов. Если в каком-то кортеже отсутствуют данные о значении атрибута, говорят, что этот атрибут допускает неопределенность (NULL). Признак NULL присваивается атрибуту, когда действительное значение не известно. NULL не эквивалентно ни нулевому значению, ни пустой строке, то есть это полная неопределенность. Внешний ключ – это множество атрибутов, которые являются первичным ключом в другом отношении. Отношение, которое содержит внешний ключ, называется ссылающимся, а отношение, которое содержит соответствующий первичный ключ, называется ссылочным. Ключи Неопределенность значений атрибутов в ключахПодмножество атрибутов схемы отношения, однозначно идентифицирующее любую запись в отношении и не имеющее собственного подмножества, также идентифицирующего любую запись в отношении, называется ключом отношения. Как следует из определения, ключ отношения должен отвечать следующим требованиям: - идентифицировать кортеж; - не содержать "лишних" атрибутов. Одно отношение может иметь несколько ключей. Ключ может состоять как из одного атрибута, так и нескольких. Во втором случае мы говорим, что ключ является составным. Ключ, который используется в данный момент называется первичным. Все остальные ключи являются возможными. При выборе первичного ключа учитывается: - Желательно, чтобы ключ был несоставной - Его значение не должно меняться в процессе жизни БД. Когда невозможно найти идентификатор, отвечающий этим требованиям вводится суррогатный ключ, значение которого является внутренним делом системы. Поскольку БД представляет собой совокупность отношений, которые должны быть связаны между собой, то должен существовать механизм организации этой связи, в котором основное место занимает так называемый внешний ключ. Внешний ключ отношения r есть множество атрибутов, которые являются первичным ключом в отношении q. ПРИМЕР: R(Студент) = {№ зачетки, Фамилия, Имя, Отчество, …} R(Успеваемость) = {№ зачетки, Название предмета, Название вида отчетности, Оценка} Внешний ключ - № зачетки. Отношение, содержащее внешний ключ, называется ссылающимся отношением (в приведенном выше примере это отношение Успеваемость). Отношение, содержащее первичный ключ, адекватный внешнему ключу другого отношения, называется ссылочным отношением (в приведенном выше примере это отношение Студент). Если некий атрибут присутствует в нескольких отношениях, то его наличие обычно отражает определенную связь между кортежами этих отношений. Недопустимо, чтобы атрибуты, входящие в первичный или внешний ключ принимали NULL значения. Если в каком то кортеже отсутствуют данные о значении атрибута, то говорят, что его значение NULL (не определено, неизвестно, неприемлемо для данного кортежа). Определитель NULL следует воспринимать как логическую величину «неизвестно». Т. е. либо это значение не входит в область определения некоторого кортежа, либо никакое значение еще не задано. Ключевое слово NULL представляет собой способ обработки неполных или необычных данных. Значение NULL не эквивалентно не нулевому численному значению, не пустой строке. Для избежания NULL значений в первичном и внешнем ключах целесообразно вводить т. н. суррогатный ключ. Методы управления параллельностьюСуществует 2 основных метода управления параллельностью, позволяющих организовать одновременное безопасное выполнение транзакций при соблюдении определенных ограничений: метод блокировки и метод временных меток. Блокировка – процедура, используемая для управления параллельным доступом к данным. Когда некоторая транзакция получает доступ к БД, механизм блокировки позволяет (с целью исключения получения некорректных результатов) отклонить попытки получения доступа к этим же данным со стороны др. транзакций. Принцип работы метода блокировок следующий: транзакция должна потребовать выполнить блокировку для чтения (S-блокировка или разделяемая – с взаимным доступом) или для записи (X-блокировка (монопольная) или эксклюзивная без взаимного доступа) некоторого элемента данных перед тем, как она сможет выполнить в БД соответствующую операцию чтения или записи. Установленный блок препятствует модификации элемента данных другими транзакциями или даже считыванию его, если этот блок был установлен для записи. Блокировка может быть выполнена для элементов самого различного размера, начиная с БД и заканчивая отдельным полем конкретной записи. Основные правила метода блокировки: 1). Если транзакция А блокирует объект при помощи Х-блокировки, то любой доступ к этому объекту со стороны другой транзакции будет отменен. 2). Если транзакция А блокирует объект с помощью S-блокировки, то запросы на Х-блокировку будут отвергнуты со стороны др. транзакций, на S-блокировку будут приняты. Доступ к объектам БД осуществляется в соответствии с протоколом доступа к данным (или протоколом блокировки), который с помощью блокировок чтения и записи позволяет избежать проблем параллельности (потеря результатов обновления, зависимость от незафиксированных результатов, несогласованная обработка данных). 1). Прежде чем прочитать объект, транзакция должна наложить на него блокировку чтения (S-блокировку). 2). Прежде чем обновить объект, транзакция должна установить для него блокировку для записи (Х-блокировку).
Необходимость управления параллельностьюУправление параллельностью – процесс организации одновременного выполнения в базе данных различных операций, гарантирующих исключение их взаимного влияния друг на друга. Важнейшей целью создания БД является организация параллельного доступа многих пользователей к общим данным, используемыми ими совместно. Обеспечить параллельный доступ относительно несложно, если все пользователи будут только читать данные, помещенные в базу. В этом случае работа каждого из них не оказывает никакого влияния на работу остальных пользователей. Однако, если два и более пользователей одновременно обращаются к базе данных и хотя бы один из них хочет обновить хранимую в базу информацию, возможно взаимное влияние процессов друг на друга, способное привести к несогласованности данных. Существуют три проблемы параллельности (возникающие при параллельной обработке транзакций): 1. Проблема потери результатов обновления; Рассмотрим ситуацию, когда транзакция А считывает некоторый кортеж t в момент t1, а транзакция В считывает этот же кортеж t в момент t2. Далее транзакция А обновляет кортеж t в момент t3 (исходя из значений в момент t1), а транзакция В обновляет тот же кортеж t в момент t4 (исходя из значений в момент t2 и аналогичных значений, которые были считаны в момент t1).
Результат операции обновления, выполненной транзакцией А, будет утерян, поскольку в момент t4 он будет перезаписан транзакцией В. 2. Проблема незафиксированной зависимости (чтение “грязных” данных, неаккуратное считывание); Может возникнуть в том случае, если любой транзакции разрешено считывание или обновление кортежа, который только что был обновлен другой транзакцией, но результаты выполнения этой транзакции еще не были зафиксированы. Если некоторое обновление не зафиксировано, то существует определенная вероятность, что оно не будет зафиксировано никогда из-за отката данной транзакции. Пример 1
Пример 2
3. Проблема несовместимого анализа; Включает 3 варианта: 1. Неповторяемое считывание; 2. Фиктивные элементы фантомы; 3. Собственно несовместимый анализ. 1. Неповторяемое считывание: Транзакция А дважды читает одну и ту же строку, между этими чтениями и вклинивается транзакция В, которая изменяет значение строки. Транзакция А ничего не знает о существовании транзакции В. А т.к. сама ничего не меняла, то и ожидает, что значение при повторном чтении будет тем же. С точки зрения транзакции А происходит самопроизвольное изменение данных.
Эффект фиктивных элементов фантомов наблюдается, когда происходит чтение нескольких строк, удовлетворяющих некоторому условию: Транзакция А производит считывание строк с одним и тем же условием. Например, считывает результаты экзамена студентов группы ИС-01. В это время вклинивается транзакция В и вставляет или удаляет n-ое количество строк. При повторном считывании транзакция А видит другое количество строк. Транзакция А ничего не знает о существовании В и не может понять, что происходит с данными.
3. Собственно несовместимый анализ: В смеси транзакций присутствуют 2 транзакции: короткая и длинная.
Таким образом, рассмотренные коллизии показывают, что если не принимать определенных мер, то нарушится одно из важнейших свойств изолированности транзакций. Очевидно, что транзакции не будут мешать друг другу, если они выполняются в разное время и работают с разными данными. Нормальные формы Общая классификация Отличие НФБК от НФКритерием, по которому определяют необходимость декомпозиции отношения, является нахождение отношения в той или иной нормальной форме. Наибольший интерес и практическую значимость представляют первая, вторая и третья исправленная (НФБК) нормальные формы. Первая нормальная форма(1НФ). Отношение находится в первой нормальной форме, если все значения его атрибутов атомарны. Понятие атомарности условно. Атомарность или ограничение на атомарность устанавливается исходя из анализа информационного обеспечения системы и структуры выходной документации (если никогда не возникнет необходимость выводить отдельно фамилию, имя и отчество, то можно принять, что ФИО атомарно). Отношение, не находящееся в 1НФ:
Отношение, находящееся в 1НФ:
При приведении к атомарному значению необходимо следить, чтобы не был утерян смысл атрибутов. Вторая нормальная форма (2НФ) Отношение находится во второй нормальной форме, если оно находится в первой нормальной форме, и каждый его неосновной атрибут функционально полно зависит от возможного ключа, т.е. не зависит ни от какого его подмножества. R={ABCD} Если ключ отношения состоит из одного атрибута, то оно всегда находится во 2-ой нормальной форме. Однако 2НФ не освобождает от избыточного дублирования. ПРИМЕР: R={ABCD} F={AB>D, A> C} D зависит функционально полно от ключа, а C – нет, следовательно отношение не находится во 2НФ. Здесь целесообразно вторую ФЗ вынести в отдельное отношение. ПРИМЕР приведения ко II НФ: дано отношение со схемой R={ABCD} и минимальным покрытием на этой схеме Fmin={A®C, C®D}. Ключом отношения является множество атрибутов {AB}. Атрибуты С и D зависят от подмножества ключа (атрибута A), следовательно, отношение не находится во 2-ой нормальной форме. При этом избыточное дублирование и все, связанные с этим аномалии возникают на атрибутах, зависящих от собственного подмножества ключа.
 Третья нормальная форма (3НФ) Отношение находится в третьей нормальной форме, если оно находится во второй нормальной форме, и каждый неосновной атрибут его схемы нетранзитивно зависит от возможного ключа (т.е. напрямую) Пример: R={ABC}, F={A>B, B>C}. Декомпозируется на R/={AB}, R//={BC}.
НФБК (Нормальная форма Бойса-Кодда) Отношение находится в НФБК, если оно находится в 1НФ и каждый детерминант является возможным ключом (или ключом является вся схема отношения). Пример:
Декомпозиция до НФБК осуществляется на минимальном покрытии. В исходном отношении выявляется множество возможных ключей и детерминант. Если выясняется, что эти два множества неэквивалентны, то в отдельное отношение выделяется крайняя ф.з. Если после этого множества детерминантов и ключей оказываются эквивалентными, то декомпозиция заканчивается. В противном случае, продолжается выделение ф.з. пошагово, по одной на каждом шаге. Любая декомпозиция прошла успешно, если все ф.з., имеющиеся в исходной базе данных были сохранены в новом проекте, т.е. говорят, что все ф.з. навязаны базе данных. Пример: R={ABC} F={A>B, B>C}. Декомпозируется на 2 отношения: R={AB}, R={BC}. Все ф.з., имеющие место в исходном отношении сохранены: F/={A>B}, F//={B>C}. Отличие НФБК от 3 НФ. НФБК учитывает Ф/З, в которых участвуют все потенциальные ключи отношения, а не только его первичный ключ. Для отношения с единственным потенциальным ключом его 3НФ и НФБК являются эквивалентами. Например, R = {ABC} и множество Ф/З F = { A>B, B>С, C>A}. Отношение не находится в 3НФ, а нуждается в декомпозиции – есть транзитивные зависимости. Но несмотря на их наличие, какие-либо аномалии в этом отношении отсутствуют. Значит, декомпозиция не требуется. Особенность этого отношения заключается в том, что все детерминанты в нем являются возможными ключами. Определение 3НФ не позволяет учесть эти частные случаи, в связи с этим была предложена НФБК. Практическая значимость понятий: замыкания ФЗ, замыкание атрибутовПонятие ФЗ: ФЗ определяют однозначное соответствие м/у значениями атрибутов. ПР1: A>B {А определяет В, А и В принадлежат некоторой схеме R}. ПР2: ТАБ_№>ФИО, ТАБ_№>квалификация Множество функциональных зависимостей, которое не может быть дополнено ни одной новой функциональной зависимостью с помощью аксиом рефлексивности, пополнения и псевдотранзитивности, называется замыканием множества функциональных зависимостей и обозначается F+. Для получения замыкания F+ используются аксиомы Армстронга. Эти аксиомы могут быть использованы для практического вычисления замыкания, так как эти правила являются полными (в том смысле, что для заданного множества ФЗ F минимальный набор ФЗ, которые подразумевают все зависимости из множества F, может быть выведен из ФЗ множества F на основе этих правил) и исчерпывающими (поскольку никакие ФЗ, которые не подразумеваются ФЗ множества F, с их помощью не могут быть выведены). Замыканием множества атрибутов {A1, A2, …, An} на схеме R есть множество атрибутов, принадлежащих схеме R и функционально зависящих от A1, A2, …, An. Обозначается замыкание как {A1,A2,…,An}+. Два множества ФЗ-ей эквивалентны, если имеют одно и тоже замыкание множеств ФЗ. Два множества атрибутов (принадлежат одному классу эквивалентности) эквивалентны, если они имеют одинаковое замыкание. Если замыканием того или иного множества атрибутов является вся схема отношения, то очевидно, что это множество, по крайней мере, является суперключом. Для того, чтобы определить ключ, необходимо проверить, есть ли в исходном множестве атрибутов собственное подмножество, у которого замыканием является также вся схема отношения, и оно в свою очередь не содержит аналогичного собственного подмножества. Пусть дано множество функциональных зависимостей F={A®B, B®C} , на схеме R={ABC} отношения r. Докажем, что ключом данного отношения будет атрибут А. С этой целью построим замыкания для всех атрибутов левых частей функциональных зависимостей (см. Таблица 6). Таблица 6
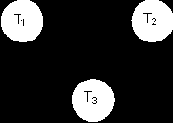
Таким образом, атрибут А является ключом отношения, так как от него функционально зависят все атрибуты схемы отношения. Очевидно, что замыканием множеств AB, AC, ABC тоже будет вся схема отношения, однако они не будут являться ключами, поскольку содержат внутри себя ключи. Проблемы декомпозиции на минимальном покрытии Теорема ХезаПроблема возникает тогда, когда отношение имеет несколько ключей. Например, отношение R = {A,B,C} и множество Ф/З на этой схеме F = { AB®C, C®B}. Возможные ключи AB и AC, при этом AC не детерминант. В отношении наблюдается аномалия, обусловленная тем, что атрибут B, являясь основным атрибутом зависит от собственного подмножества второго ключа AC, т.е. исходное отношение не находится во 2 НФ. Традиционное выделение в отдельное отношение Ф/З не позволяет решить проблему – появляется новое отношение, со схемой R={C,B}, но при этом сохраняется исходное отношение, что приводит к “абсурду” (избыточность и внедрение дополнительных механизмов, поддерживающих это избыточность). Решить возникшую проблему можно используя теорему Хеза. Пусть дано отношение со схемой: R = {A, B, C} и множеством Ф/З на этой схеме F = {AB®C, C®B}. Декомпозиция без потерь будет состоять из двух отношений – R1 = {CA} и R2 = {CB}. При этом, остается потерянной зависимость AB®C. Ее необходимо поддерживать программным путем. Распределённая взаимная блокировкаЛюбые алгоритмы управления параллельностью, использующие механизмы блокировок, могут приводить к появлению в системе ситуации взаимной блокировки процессов (тупиковая ситуация, которая может возникнуть, когда 2/более транзакции находятся во взаимном ожидании освобождения блокировок, удерживаемых каждой из них). Пример. · Транзакция Т1 запускается на сайте S1 и создает агента на сайте S2. · Транзакция Т2 запускается на сайте S2 и создает агента на сайте S3. · Транзакция Т3 запускается на сайте S3 и создает агента на сайте S1. Эти транзакции устанавлиают блокировки таким образом, что образуется взаимная блокировка по следующей схеме:
Графы ожидания для сайтов
Комбинированный граф ожидания для сайтов В СУРБД для выявления ситуаций взаимной блокировки недостаточно использовать обычные (локальные) графы ожидания, необходимо также строить глобальный граф ожидания (объединение всех локальных графов ожидания). Существует 3 общих метода выявления взаимных блокировок в СУРБД: централизованный, иерархический и распределенный. Централизованный метод выявления взаимных блокировок, при этом методе один из сайтов системы назначается координатором выявления взаимных блокировок (DDC). Сайт DDC отвечает за построение и обработку глобального графа ожидания. С определенным интервалом каждый менеджер блокировки в системе направляет в адрес DDC свой локальный граф ожидания. Сайт DDC выполняет построение глобального графа ожидания и проверяет его на наличие циклов, если граф содержит 1/более циклов, DDC должен разрушить их, выбрав те транзакции, которые должны быть отменены с выполнением отката, а затем перезапущены. Для минимизации количества пересылаемых данных каждый менеджер блокировки посылает сведения только об удалении/добавлении ребер в локальном графе ожидания, произошедшие с момента последней отправки сведений. Недостаток данного метода: снижение надежности всей системы, т.к.
пересылает свой граф ожидания только тому сайту (SK), на котором ожидает соответствующая транзакция (Тк). Если tS(Ti)<tS(TK), то для проверки наличия взаимной блокировки сайт S1 должен переслать свой локальный граф на сайт SK. Сайт SK добавляет полученную информацию к своему локальному графу ожидания и проверяет результат на наличие циклов, не включающих узел ТEXT. Если таких циклов нет, то процесс выполняется или до появления цикла, или до построения полного глобального графа ожидания, не содержащего циклов (взаимные блокировки в системе отсутствуют). Доказано, что если в системе существует глобальная взаимная блокировка, то описанная выше процедура непременно вызовет появление цикла в графе ожидания одного из сайтов. Разработка распределённых баз данныхРазработка централизованной реляционной БД делится на три этапа проектирования: 1. Концептуальное проектирование – создание концептуального представления БД, включающее определение типов важнейших сущностей и существующих между ними связей. 2. Логическое проектирование – преобразование концептуального представления в логическую структуру БД, включая проектирование отношений(процесс конструирования информационной модели на основе существующих конкретных моделей данных, не зависимой от используемой СУБД и др. физических условий реализации). 3. Физическое проектирование – принятие решений о том, как логическая модель будет физически реализована в БД, создаваемой с помощью выбранной СУБД. Рассмотрим ряд дополнительных факторов, которые должны учитываться при разработке распределенных БД: 1. Фрагментация – любое отношение может быть разделено на некоторое количество частей, называемых фрагментами, которые затем распределяются по различным сайтам. Существует 2 основных типа фрагментов: горизонтальные и вертикальные. Горизонтальные - подмножества кортежей, вертикальные – подмножества атрибутов. 2. Распределение – каждый фрагмент сохраняется на сайте, выбранном с учетом «оптимальной» схемы их размещения. 3. Репликация – СУРБД может поддерживать актуальную копию некоторого фрагмента на нескольких различных сайтах. Проектирование должно выполняться на основе на основе как количественных так и качественных показателей. Количественная информация используется в качестве основы для распределения, а качественная служит базой при создании схемы фрагментации. Количественная информация включает показатели: 1) Частота запуска приложения на выполнение. 2) Сайт, на котором запускается приложение. 3) Требования к производительности транзакций и приложений. Качественная информация может включать перечень выполняемых в приложении транзакций, используемые отношения, атрибуты и кортежи, к которым осуществляется доступ, тип доступа (чтение/запись), предикаты, используемые в операциях чтения. Цели фрагментации: 1) Локальность ссылок - данные должны храниться как можно ближе к местам их пользования. 2) Повышение надежности и доступности за счет использования механизма репликации. 3) Приемлемый уровень производительности, неверное распределение данных приводит к возникновению в системе узких мест, что снижает производительность всей системы. 4) Баланс между емкостью и стоимостью внешней памяти. 5) Минимизация расходов на передачу данных. Реализация запросов средствами SQLНазначение оператора SELECT состоит в выборке и отображении данных одной или более таблиц БД. Это мощный оператор, способный выполнять действия, эквивалентные операторам реляционной алгебры. Общий формат оператора SELECT имеет следующий вид: SELECT [DISTINCT] *|<столбец> [<псевдоним>] [,<групповая функция>] [,…n] FROM <таблица>[, …n]| (<подзапрос>) [WHERE <условие>] [GROUP BY<выражение группировки>] [HAVING <условие отбора группы>] [ORDER BY < столбец >[,…n]] Ключевое слово DISTINCT используется для возвращения запросом только уникальных строк. При необходимости вывести все записи из отношения используется команда SELECT *. Оператор SELECT устанавливает какие столбцы должны присутствовать в выходных данных. Оператор FROM определяет имена используемой таблицы или нескольких таблиц. WHERE выполняет фильтрации строк объекта в соответствии с заданными условиями. GROUP BY образуются группы строк, имеющих одно и то же значение в указанном столбце. HAVING фильтрует группы строк объекта в соответствии с указанным условием. ORDER BY определяет упорядоченность результатов выполнения оператора. Порядок предложений и фраз в операторе SELECТ не может быть изменен. Только предложения SELECT и FROM являются обязательными, все остальные предложения и фразы могут быть опущены. Операция SELECT является закрытой, т.е. результат запроса к таблице представляет собой др. таблицу. Приведем пример запроса: вывести названия всех предметов, по которым средняя оценка меньше 4. SELECT Name_Subject, AVG(Mark) FROM Progress Pr, Subject S WHERE Pr.Code_Subject=S.Code_Subject GROUP BY Name_Subject HAVING AVG(Mark)<4 Обобщающая функция AVG возвращает усредненное значение в указанном столбце. Стандарт ISO содержит определение 5 обобщающих функций: 1.COUNT возвращает количество значений в указанном столбце. 2.SUM возвращает сумму значений в указанном столбце. 3.AVG. 4.MIN возвращает минимальное значение в указанном столбце. 5.MAX возвращает максимальное значение в указанном столбце. Запрос, в котором присутствует фраза GROUP BY называется группирующим запросом; столбцы, перечисленные в данной фразе называются группируемыми столбцами. Все имена столбцов, приведенные в предложении SELECT, должны присутствовать и во фразе GROUP BY. За исключением случаев, когда имя столбца используется в обобщающей функции. Предложение ORDER BY всегда ставится в конец команды SELECT. По умолчанию сортировка идет по возрастанию. Для изменения порядка сортировки используется опция DESC. При сортировке по нескольким столбцам столбцы перечисляются через запятую. ORDER BY всегда стоит в конце запроса. Пример: Вывести список имен оценок студентов, расположив их по возрастанию имен и оценок. SELECT DISTINCT Sname ФИО FROM Student, Progress WHERE Student.N_record_book= Progress.N_record_book; ORDER BY Sname Составные части языка SQLSQL является примером языка предназначенного для работы с таблицами с целью преобразования входных данных к требуемому выходному виду. Язык SQL имеет два основных компонента: язык DDL (Data Definition Language), предназначенный для определения базы данных: CREATE – создание таблицы; DROP – удаление таблицы; ALTER – внесение изменений в описание таблицы, в том числе: добавление и изменение столбцов; добавление, разрешение, запрет и удаление ограничений). язык DML (Data Manipulation Language), предназначенный для выборки и обновления данных: INSERT – ввод новых строк в таблицу; DELETE – удаление строк из таблицы; UPDATE – редактирование данных в таблице; SELECT – оператор выбора. Транзакция и ее свойстваТранзакция - действие или серия действий, выполняемых одним пользователем или прикладной программой, которые осуществляют доступ или изменение содержимого БД. Транзакция является логической единицей работы, выполняемой в БД. Она может быть представлена отдельной программой, являться частью алгоритма программы или даже отдельной командой (например, insert, update в SQL) и включать произвольное количество операций, выполняемых в БД. С точки зрения БД, выполнение программы некоторого приложения может расцениваться как серия транзакций, в промежутках между которыми выполняется некоторая обработка данных, осуществляемая вне среды БД. Любая транзакция всегда должна переводить базу данных из одного согласованного состояния в другое, хотя допускается, что согласованность состояния базы будет нарушаться в ходе выполнения транзакции. Любая транзакция завершается одним из двух возможных способов. В случае успешного завершения результаты транзакции фиксируются (commit) в БД, и транзакция переходит в новое согласованное состояние. Если выполнение транзакции не прошло успешно, она отменяется, в этом случае в БД должно быть восстановлено то согласованное состояние, в котором она находилась до начала данной транзакции. Этот процесс называется откатом (roll back) транзакции. Зафиксированная транзакция не может быть отменена. Если оказывается, что зафиксированная транзакция была ошибочной, потребуется выполнить другую транзакцию, отменяющую действия, выполненные первой транзакцией. В большинстве языков манипулирования данными для указания границ отдельных транзакций используются операторы BEGIN TRANSACTION, COMMIT и ROLLBACK. Свойства транзакций. Существуют некоторые свойства, которыми должна обладать любая из транзакций, это 4 основных свойства (ACID-аббревиатура, составленная из первых букв их английских названий). Атомарность. Это свойство типа «все или ничего». Любая транзакция представляет собой неделимую единицу работы, которая может быть выполнена либо вся целиком, либо не выполнена вовсе. Согласованность. Каждая транзакция должна переводить БД из одного согласованного состояния в другое согласованное состояние. Внутри транзакции система может находиться в несогласованном состоянии. Изолированность. Все транзакции выполняются независимо одна от другой. Другими словами, промежуточные результаты незавершенной транзакции не должны быть доступны другим транзакциям. Продолжительность. Результаты успешно завершенной транзакции должны сохраняться в БД постоянно и не должны быть утеряны в результате последующих сбоев. Транзакция начинается с момента присоединения пользователя к СУБД. Транзакция будет завершена, если будут выполнены: 1. Ввод оператора COMMIT означает успешное завершение транзакции. После его выполнения, внесенные в БД изменения, приобретают постоянный характер. После обработки оператора commit ввод любого, инициирующего транзакцию оператора, автоматически вызовет запуск новой транзакции. 2. Команда DDL. 3. Произойдет штатный выход из системы. Транзакция не будет завершена, если: 1. Подана команда ROLLBACK. Она означает отказ от завершения транзакции, в результате чего выполняется откат всех изменений в БД, внесенных при выполнении этой транзакции. После обработки оператора rollback ввод любого, инициирующего транзакцию оператора, автоматически вызовет запуск новой транзакции. 2. Если произошло некорректное завершение сеанса работы в СУБД. 3. Если произошел какой-то сбой в системе. Трёхуровневая архитектура ANSI-SPARCANSI-SPARC - Комитет планирования стандартов и норм SPARC (Standards Planning and Requirements Committee) Национального Института Стандартизации США (American National Standard Institute - ANSI). Комитете ANSI/SPARC признал необходимость использования трехуровневого подхода общей архитектуры СУБД. Выделены 3 уровня абстракции, т.е. трех различных уровней описания элементов данных. Эти уровни формируют трехуровневую архитектуру, которая охватывает внешний, концептуальный и внутренний уровни. Цель трехуровневой архитектуры заключается в отделении пользовательского представления базы данных от ее физического представления. Причины, по которым желательно выполнять такое разделение: 1. Каждый пользователь должен иметь возможность обращаться к одним и тем же данным, используя свое собственное представление о них. Каждый пользователь должен иметь возможность изменять свое представление о данных, причем это изменение не должно оказывать влияние на других пользователей. 2. Пользователи не должны непосредственно иметь дело с такими подробностями физического хранения данных в базе, как индексирование и хеширование . Иначе говоря, взаимодействие пользователя с базой не должно зависеть от особенностей хранения в ней. 3. Администратор базы данных (АБД) должен иметь возможность изменять структуру хранения данных в базе, не оказывая влияния на пользовательские представления. 4. Внутренняя структура базы данных не должна зависеть от таких изменений физических аспектов хранения информации, как переключение на новое устройство хранения. 5. АБД должен иметь возможность изменять концептуальную или глобальну. Структуру базы данных без какого-либо влияния на всех пользователей. 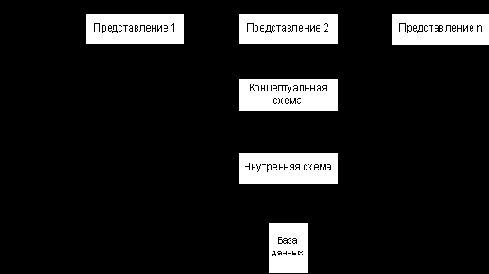 Внешний уровень – представление базы данных с точки зрения пользователей. Этот уровень описывает ту часть базы данных, которая относится к каждому пользователю.
Управление распределённой параллельностьюХороший механизм управления параллельностью в распределенной СУБД должен обеспечивать: 1. устойчивость к отказам на сайтах и в линиях; 2. высокий уровень параллельности, удовлетворяющий существующим требованиям производительности; 3. невысокий дополнительный уровень потребления времени процессора и других системных ресурсов; 4. удовлетворительные показатели работы с сетевыми соединениями, имеющими высокое значение времени задержки соединения; 5. отсутствие дополнительных ограничений на структуру атомарных действий. Управление параллельностью – процесс организации одновременного выполнения в базе данных различных операций, гарантирующий исключение их взаимного влияния друг на друга. Обеспечить параллельный доступ нескольких пользователей к БД относительно несложно, если все пользователи будут читать данные. В этом случае работа каждого из них не оказывает никакого влияния на работу остальных пользователей. Но, если хотя бы один из этих пользователей имеет целью обновить хранимые данные, то возможно влияние процессов друг на друга, которое может привести к несогласованности данных. Например, возникают такие проблемы, как проблема потерянного обновления (это когда результаты вполне успешно завершенной операции обновления одной транзакции могут быть перекрыты результатами выполнения другой транзакции), проблема зависимости от нефиксированных результатов (если одна из транзакции получит доступ к промежуточным результатам выполнения другой транзакции до того, как они будут зафиксированы в базе данных), проблема несогласованной обработки (когда транзакция считывает несколько значений из базы данных, после чего вторая транзакция обновляет некоторые из этих значений непосредственно во время выполнения первой транзакции). Все эти проблемы имеют место и в распределенной среде, однако здесь еще присутствуют некоторые сложности, вызванные распределенным хранением данных. Одна из них называется проблема согласованности многих копий данных и возникает в тех случаях, когда существует больше одной копии элемента данных, размещенных в различных местоположениях. Очевидно, что для поддержки согласованности глобальной базы данных при обновлении реплицируемого элемента данных на одном из сайтов необходимо отразить это изменение и во всех остальных копиях данного элемента. Если обновление не будет отражено во всех копиях, база данных перейдет в несогласованное состояние. Предположим, что обновление реплицируемых элементов выполняется в системе синхронно, как часть транзакции, включающей исходную операцию обновления. Уровни моделирования базы данных1. Концептуальное проектирование БД - процесс создания модели информации , используемой на предприятии и не зависящей от любых физических аспектов ее представления. Концептуальный уровень моделирования заключается в создании концептуальной модели (КМ) данных для анализируемой части предприятия. Эта модель данных создается на основе информации, записанной в спецификациях требований пользователей. Концептуальное моделирование БД абсолютно не зависит от таких подробностей ее реализации, как тип выбранной целевой СУБД, набор создаваемых прикладных программ, используемые языки программирования, тип выбранной вычислительной платформы и т.д. В основе КМ лежит понятие сущности – класс объектов, представляющих интерес в рамках данной задачи (Пр: класс-студент, объекты – студент Иванов, студент Петров (объекты-ФИО, преподаватель и т.п. ??? неправильно)). Каждая сущность должна иметь уникальное имя в рамках конкретной модели, которое отражается в качестве существительного в именительном падеже и единственном числе. Каждая сущность должна иметь ключ. Концептуальный уровень моделирования включает этапы: 1. Изучение предметной области. 1.1. Определяется цель автоматизации. 1.2. Выявляется, с чьей точки зрения, будет создаваться проект. Выявляются основные процессы, подлежащие автоматизации 2. Определение типов сущностей. 3. Определение типов связей. 4. Определение атрибутов и связывания их с типами сущностей и связей. 5. Определение доменов атрибутов. 6. Определение атрибутов, являющихся потенциальными и первичными ключами. 7. Специализация или генерализация типов сущностей (необязательный этап). 8. Создание диаграммы «сущность-связь». 9. Обсуждение локальных концептуальных моделей данных с конечным пользователем. 10. Корректировка модели. 2. Логическое проектирование БД – процесс конструирования информационной модели предприятия на основе существующих конкретных моделей данных. Фаза логического проектирования БД заключается в преобразовании КМ в логическую (ЛМ) данных предприятия с учетом выбранного типа СУБД (пр.: реляционная). На уровне логического моделирования рассматривается необходимость в связях 1:1, удаляются все связи типа m к n (множественные связи – ввод слабых сущностей) и рекуррентные связи (связи, в которых одни и те же сущности участвуют несколько раз и в разных ролях; связи, в которых сущность некоторого типа взаимодействует сама с собой). Логический уровень моделирования включает этапы: 1. Построение и проверка локальной логической модели данных на основе представления о предметной области каждого из типов пользователей. 1.1. Преобразование концептуальной модели данных в логическую модель. 1.2. Определение набора отношений исходя из структуры логической модели данных. 1.3. Проверка модели с помощью правил нормализации. 1.4. Проверка модели в отношении транзакций пользователей. 1.5. Создание диаграмм “сущность-связь”. 1.6. Определение требований поддержки целостности данных. 1.7. Обсуждение разработанных локальных логических моделей данных с конечными пользователями. 2. Создание и проверка глобальной логической модели данных. 3. Проверка возможностей расширения модели в будущем. 4. Создание окончательного варианта диаграммы «сущность-связь». 5. Обсуждение глобальной логической модели данных с пользователями. Если КМ содержит рекурсивные связи, они должны быть устранены посредством определения некоторой промежуточной сущности и все связи должны быть заменены на 1:n или 1:1. Если в КМ присутствуют связи типа m:n («многие-ко-многим»), то их следует устранить путем определения некоторой промежуточной сущности (слабой). Связь типа m: n заменяется двумя связями типа 1:n, устанавливаемыми со вновь созданной сущностью. На этом уровне удаляются все связи со свободными атрибутами, удаляются сложные атрибуты, заменяются простыми, удаляются вычисляемые атрибуты. Проверяются все связи и при необходимости удаляются все избыточные. Однако на этом этапе игнорируются все остальные аспекты выбранной СУБД – например, любые особенности физической её структур хранения данных и построение индексов. Построение ЛМ данных является источником информации для этапа физического проектирования. 3. Физическое проектирование БД – процесс создания описания конкретной реализации БД, размещаемой во вторичной памяти. Предусматривает описание структуры хранения данных и методов доступа, предназначаемых для осуществления наиболее эффективного доступа к информации. При логическом проектировании разработчик сосредотачивается на том, что надо сделать, тогда как при физическом проектировании он ищет способ, как это сделать. Этап физического проектирования БД имеет обратную связь с логическим проектированием. Физический уровень моделирования включает этапы: 1. Перенос глобальной логической модели данных в среду целевой СУБД 1.1. Проектирование таблиц БД в среде целевой СУБД 1.2. Реализация бизнес правил предприятия в среде целевой СУБД 2. Проектирование физического представления БД. 2.1. Анализ транзакций 2.2. Выбор файловой структуры 2.3. Определение вторичных индексов 2.4. Анализ необходимости введения контролируемой избыточности данных 2.5. Определение требований к дисковой памяти 3. Разработка механизмов защиты 3.1. Разработка пользовательских представлений (видов) 3.2. Определение прав доступа 3.3. Организация мониторинга и настройки функционирования системы. Виды декомпозиций Декомпозиция без потерьДекомпозиция отношений проводится, чтобы исключить избыточное дублирование в отношениях. Выделяют два типа декомпозиций отношений: без потерь и с потерями. Декомпозиция без потерь происходит тогда, когда после соединения вновь полученных отношений получается исходное отношение. В ряде случаев невозможно провести декомпозицию без потерь, т.к. простое выделение ФЗ в отдельное отношение не дает желаемого результата. В этом случае надо решить: · или поддерживать избыточное дублирование; · или теряем ФЗ и поддерживаем ее программным путем. Выбор должен быть обоснован. Существуют следующие виды декомпозиций (можно доб. вопрос 4.-классиф.покрытий и вопрос 5 - теорема Хеза) 1. Декомпозиция на минимальном покрытии (если в отношении только один ключ); 2. Декомпозиция на кольцевом покрытии (если в отношении несколько ключей и существуют эквивалентные левые части функциональных зависимостей); 3. Декомпозиция по теореме Хеза (если ни один из вышеперечисленных методов неприемлем или не дает желаемого результата). Смысл декомпозиции заключается в том, что исходное отношение разбивается на несколько отношений таким образом, чтобы в последствии соединение вновь образованных отношений позволило получить исходное отношение. Такая декомпозиция получила название декомпозиции без потерь. Процесс декомпозиции следует всегда начинать со следующих операций: · с определения (идентификации) всех атрибутов, подлежащих хранению в БД. · установления между ними функциональных зависимостей. Критерием, по которому определяют необходимость декомпозиции отношения, является нахождение отношения в той или иной нормальной форме. (можно добавить вопр. 7 - норм.формы). Процесс декомпозиции осуществляется поэтапно, при этом на каждом этапе (в большинстве случаев) исходное отношение разбивается только на два отношения, затем делается вывод о необходимости продолжения декомпозиции, и если она необходима, то процесс продолжается. Декомпозиция не всегда является обязательной, и в ряде случаев проектировщик должен принимать решение, выбирая между избыточностью и независимостью отношений. Декомпозиция снимает большинство проблем, связанных с выполнением операций – удаление, добавление и редактирование, за счет исключения избыточного дублирования информации. Примеры декомпозиций: Дано: R={ABC} и F={AB  Задание: Осуществить декомпозицию. 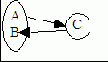 R1={CB} R1/={AB} R2={AC} R2/={CB} Декомпозиция без потерь:
  Декомпозиция с потерями:
|